Summary Statistics
Grayson White
Math 141
Week 2 | Fall 2025
Load Necessary Packages

dplyr is part of the tidyverse collection of data science packages.
Summarizing Data Visually
For a quantitative variable, want to answer:
What is an average value?
What is the trend/shape of the variable?
How much variation is there from case to case?
Need to learn key summary statistics: Numerical values computed based on the observed cases.
Measures of Center
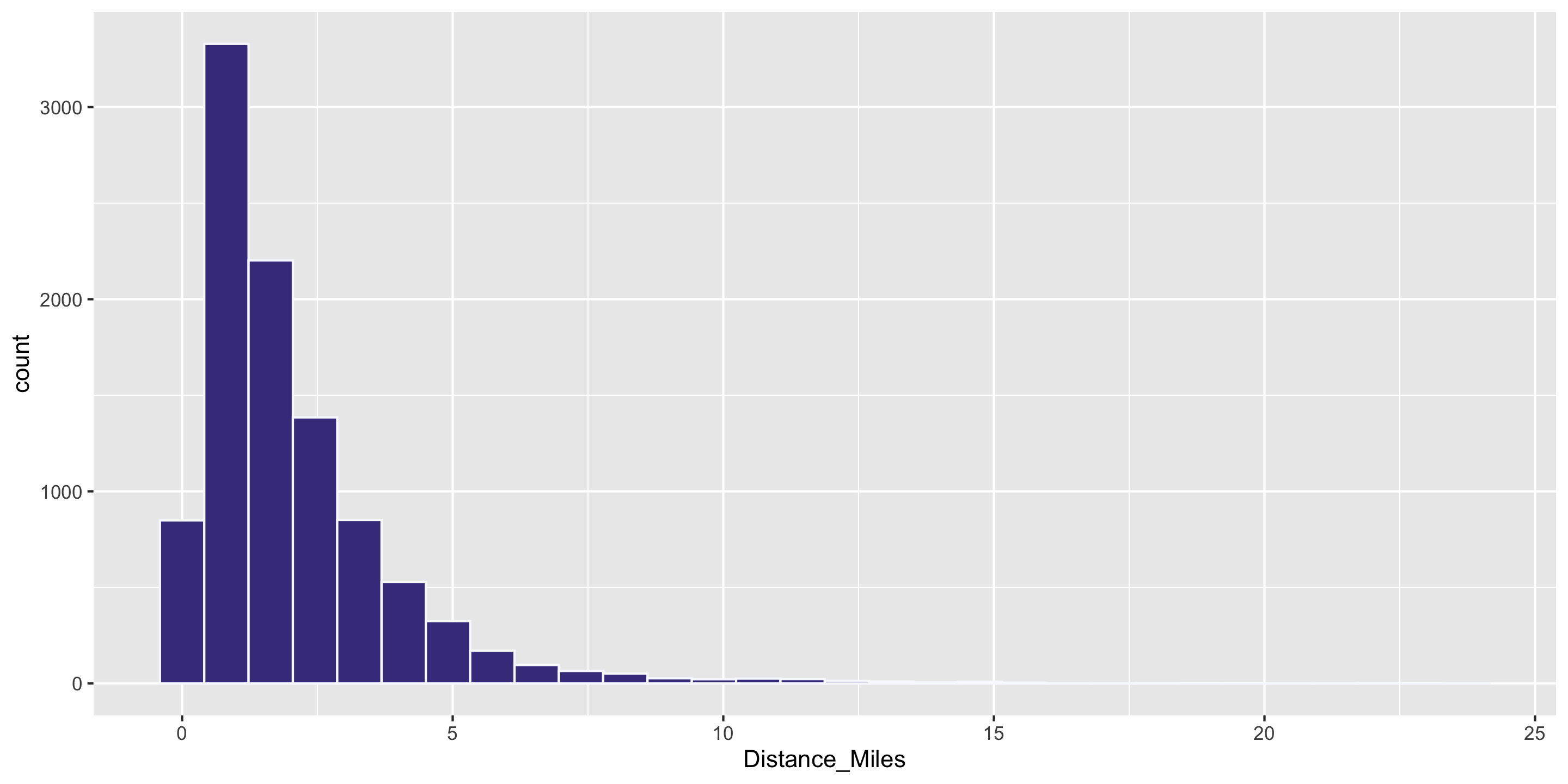
Computing Measures of Center by Groups
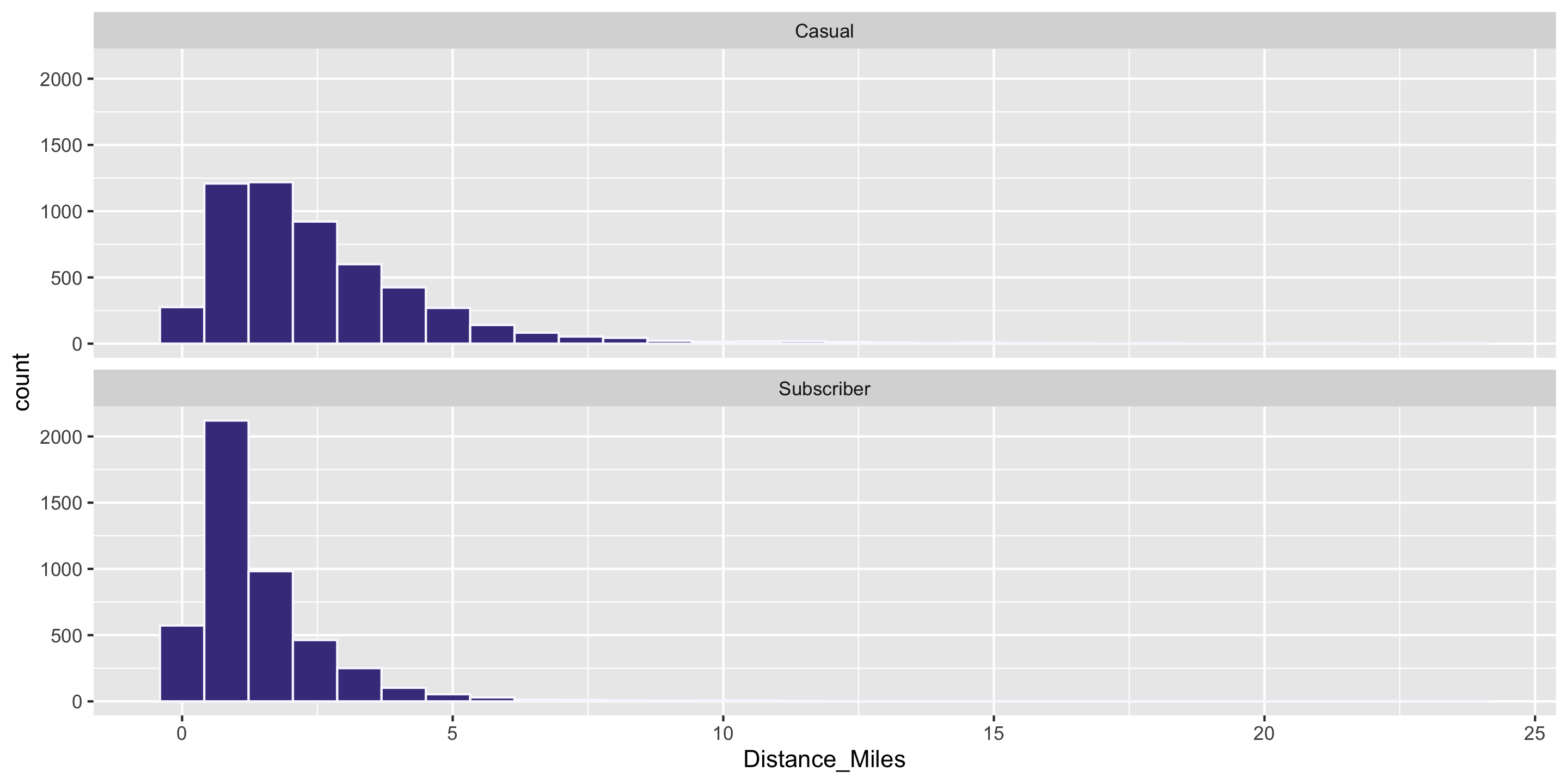
Question: Who travels further, on average? Casual biketown users or payment plan subscribers?
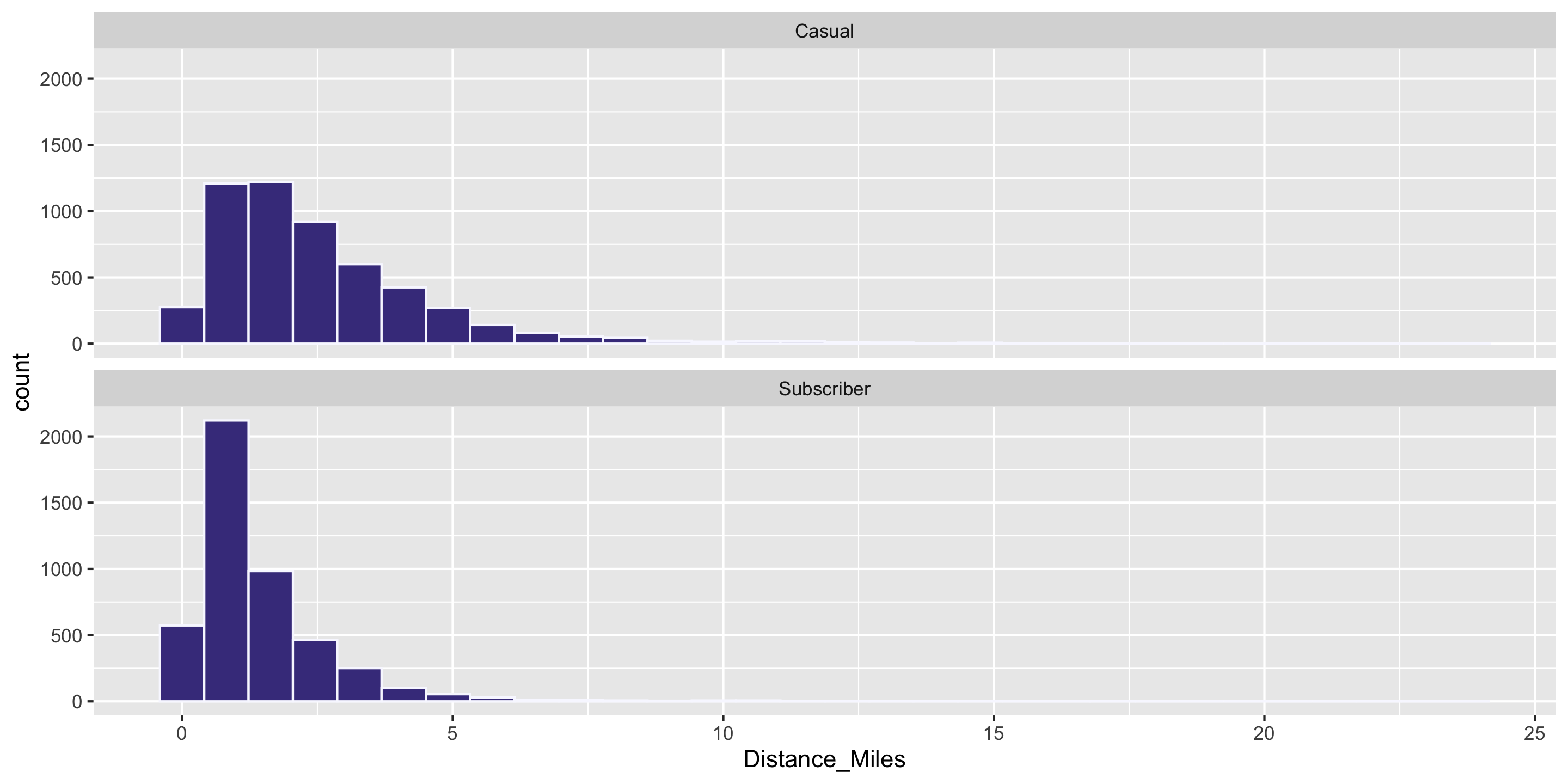
Computing Measures of Center by Groups
Compute summary statistics on the grouped data frame:
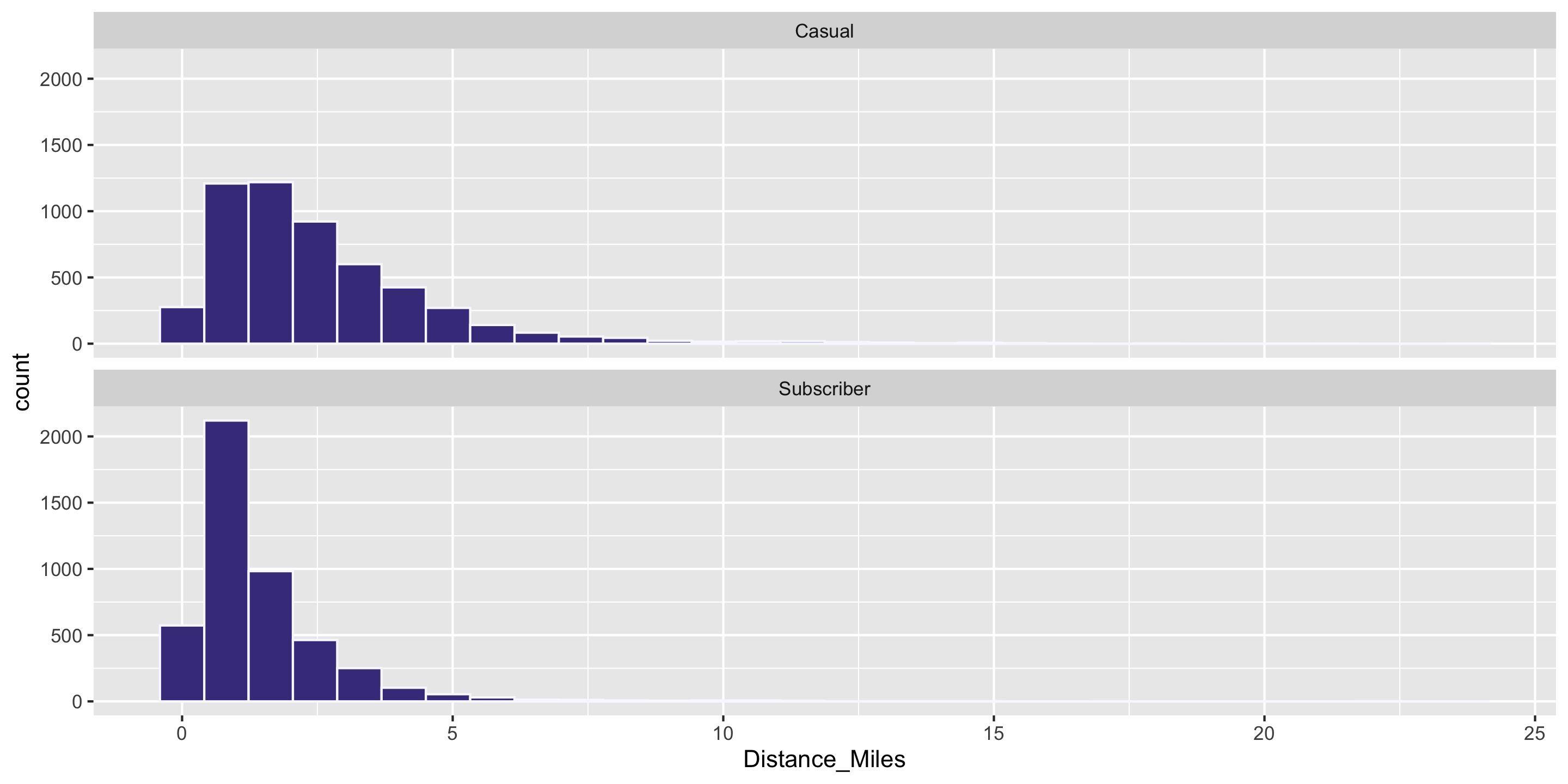
And now it is time to learn the pipe: %>%

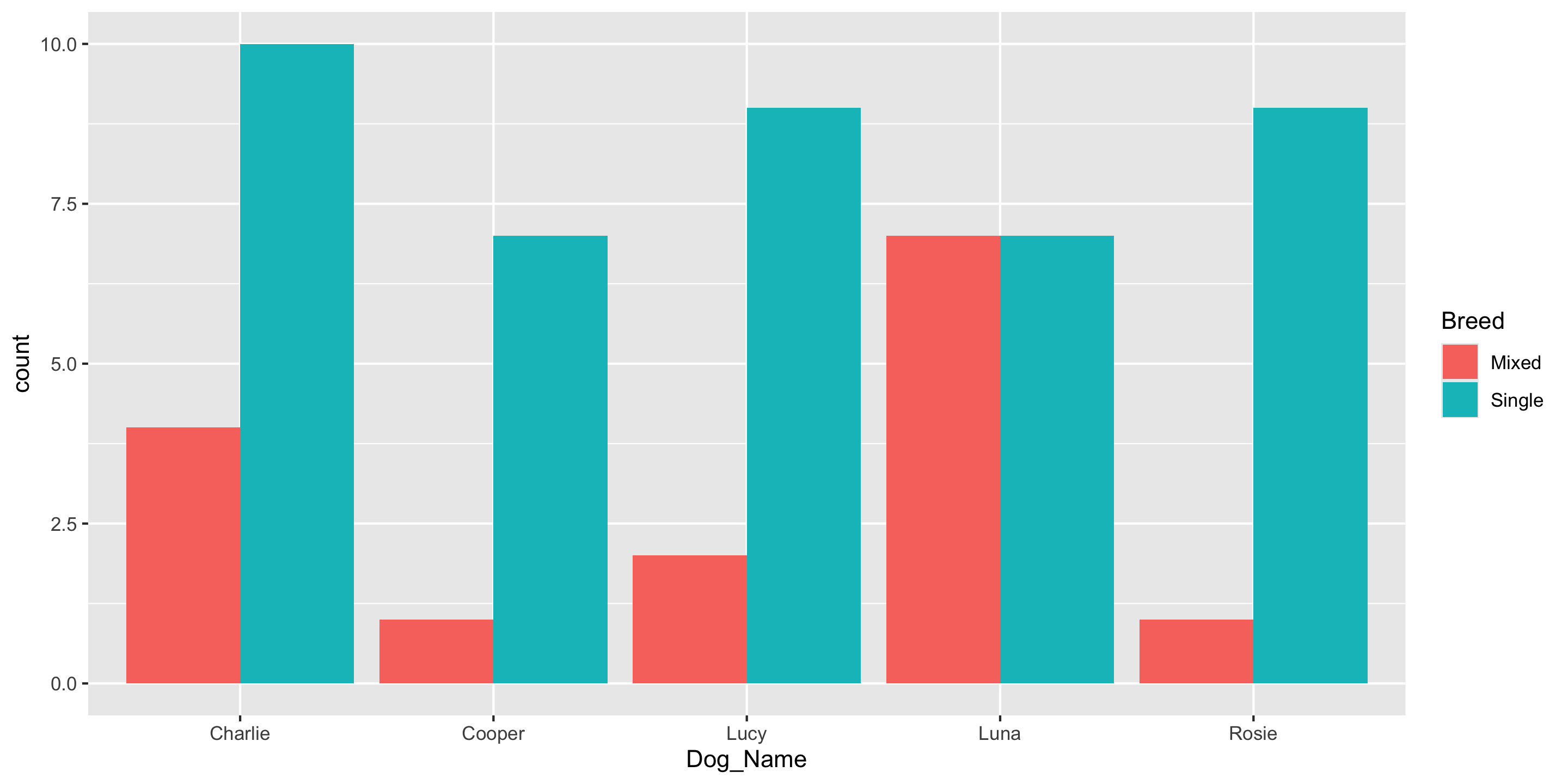
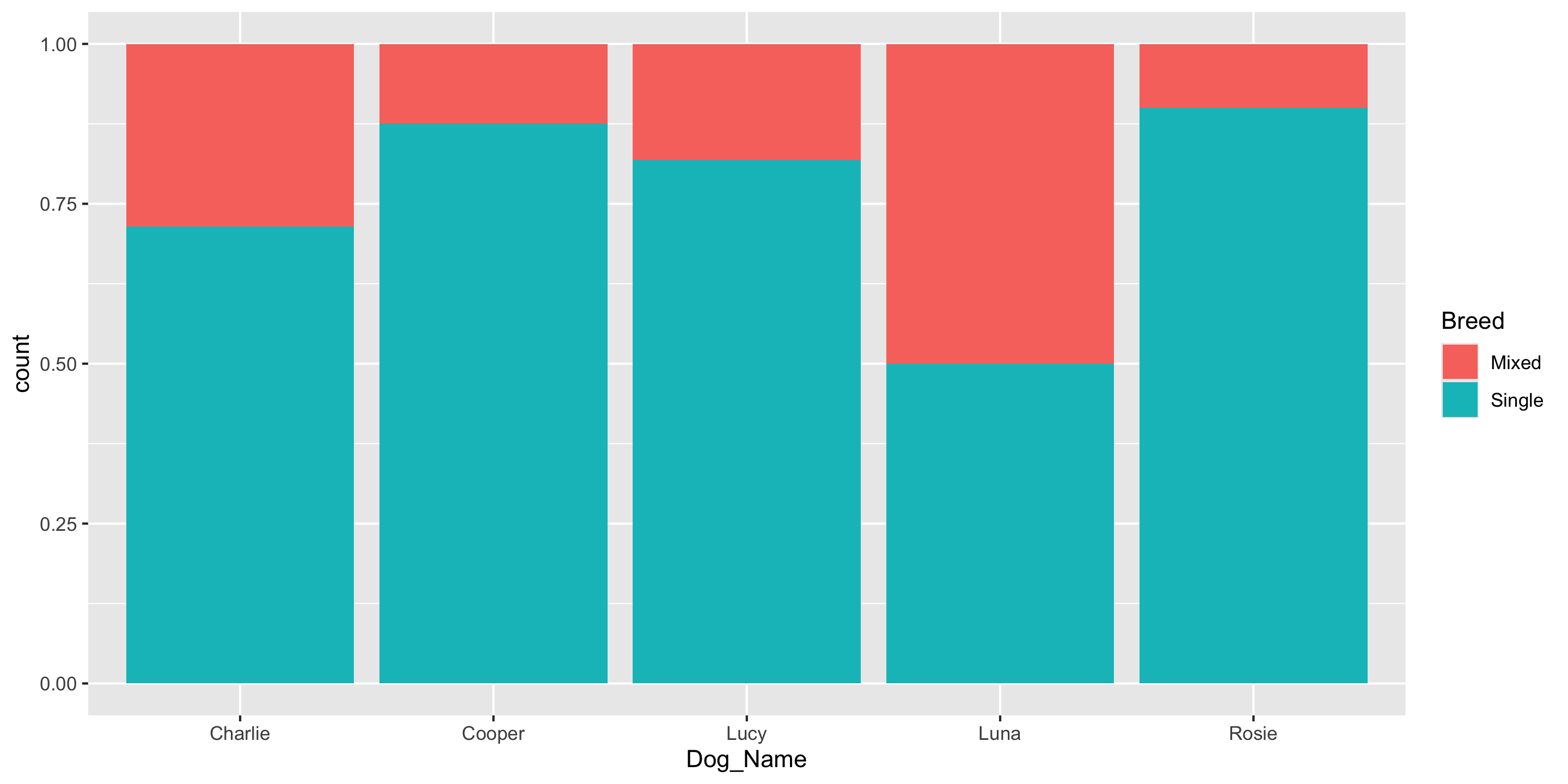
Frequency Table
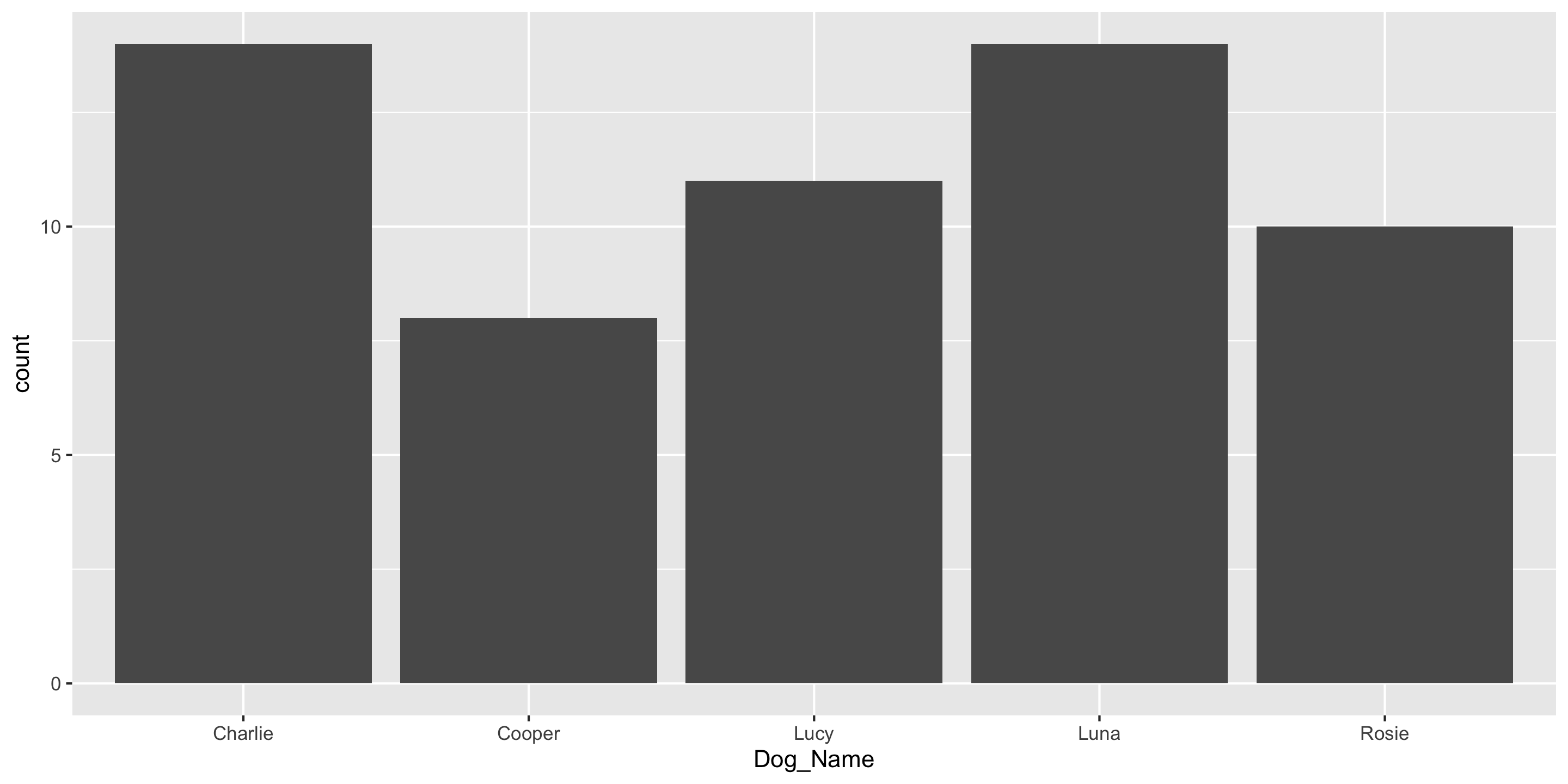
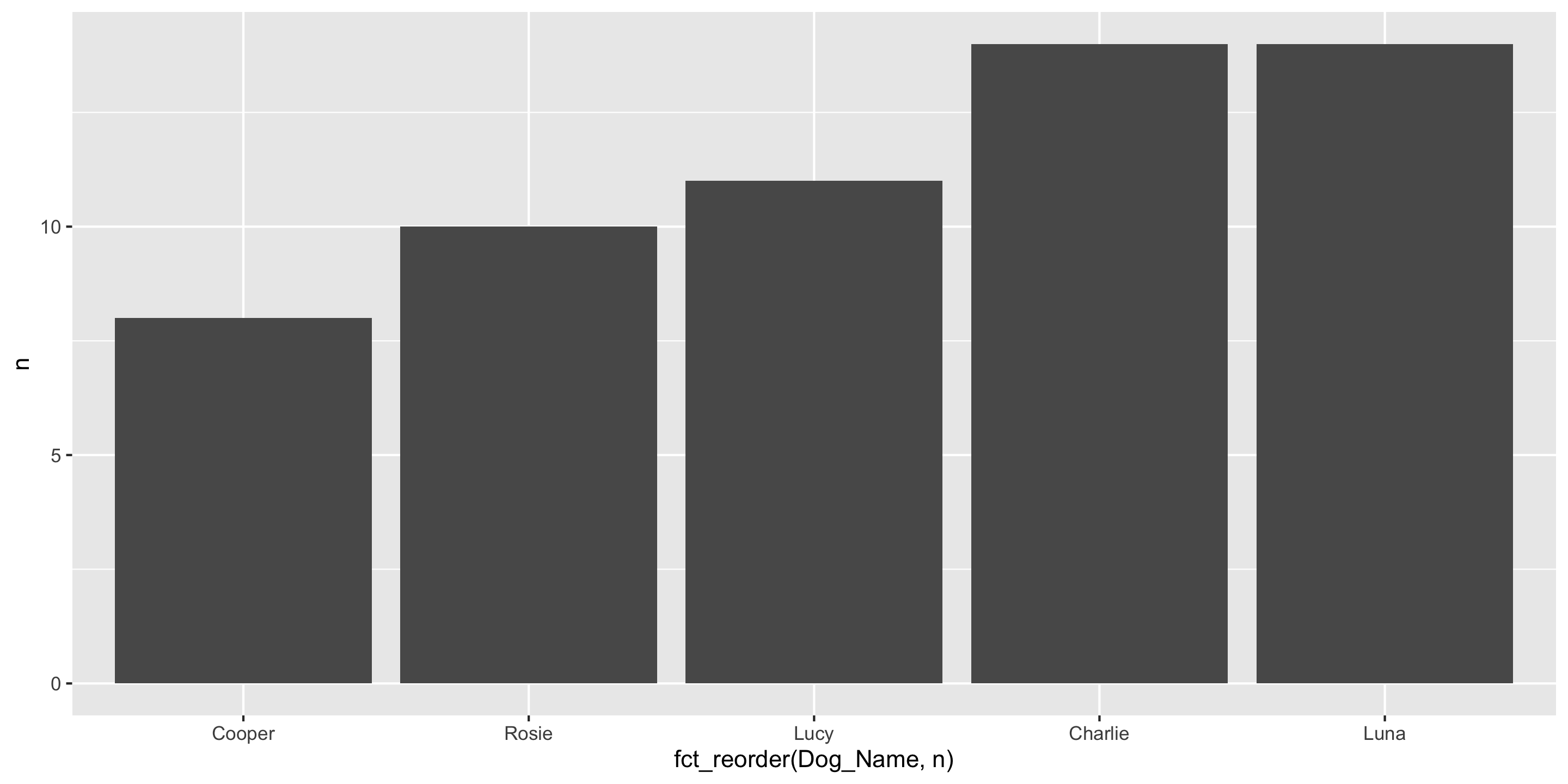
Another ggplot2 geom: geom_col()
If you have already aggregated the data, you will use geom_col() instead of geom_bar().
# A tibble: 5 × 2
Dog_Name n
<chr> <int>
1 Charlie 14
2 Cooper 8
3 Lucy 11
4 Luna 14
5 Rosie 10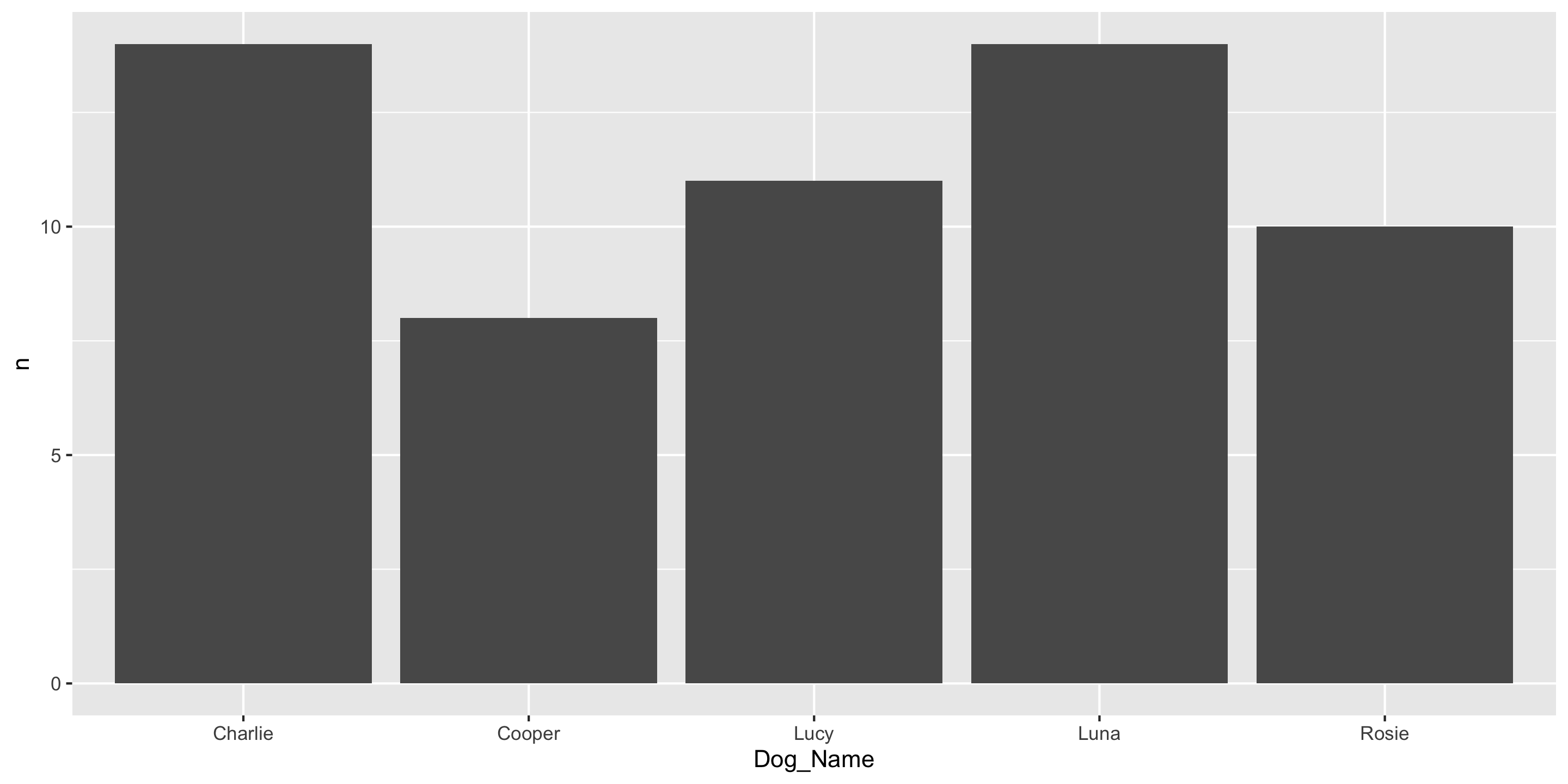
Another ggplot2 geom: geom_col()
And use fct_reorder() instead of fct_infreq() to reorder bars.
# A tibble: 5 × 2
Dog_Name n
<chr> <int>
1 Charlie 14
2 Cooper 8
3 Lucy 11
4 Luna 14
5 Rosie 10