

Simple Linear Regression I
Grayson White
Math 141
Week 4 | Fall 2025
Example: The Ultimate Halloween Candy Power Ranking
Linear trend?
Direction of trend?
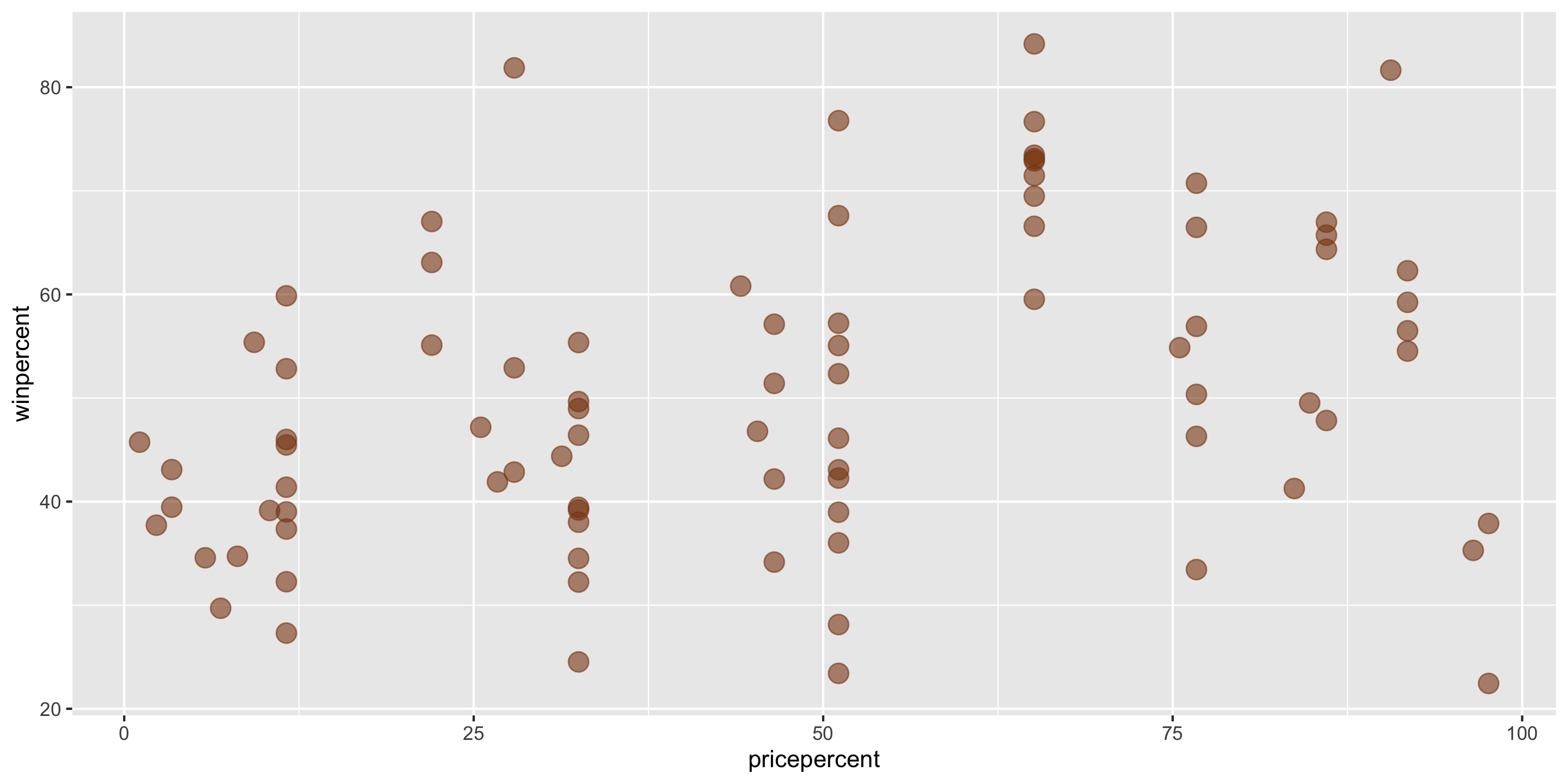
Example: The Ultimate Halloween Candy Power Ranking
A simple linear regression model would be suitable for these data.
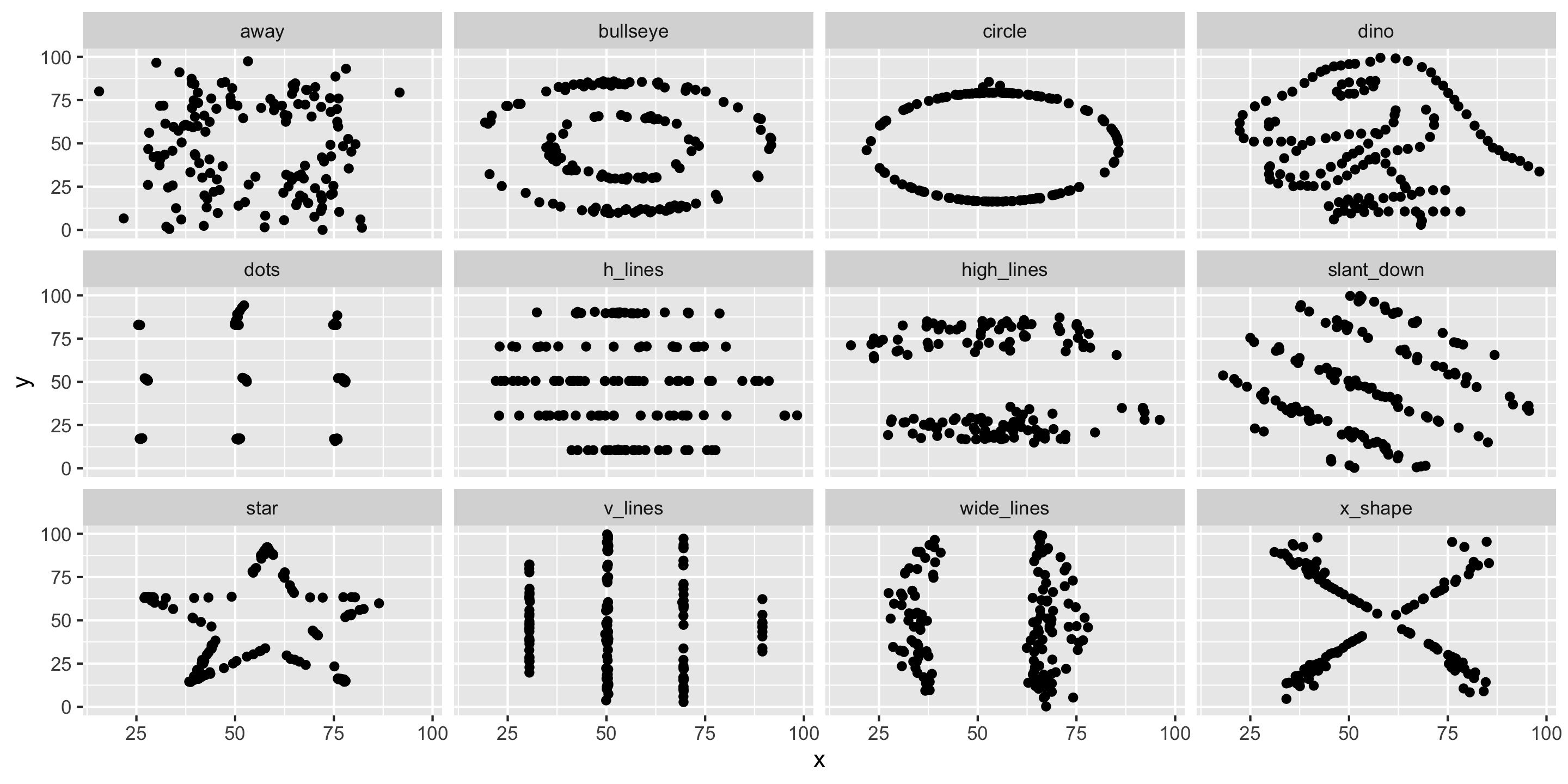
But first, let’s describe more plots!
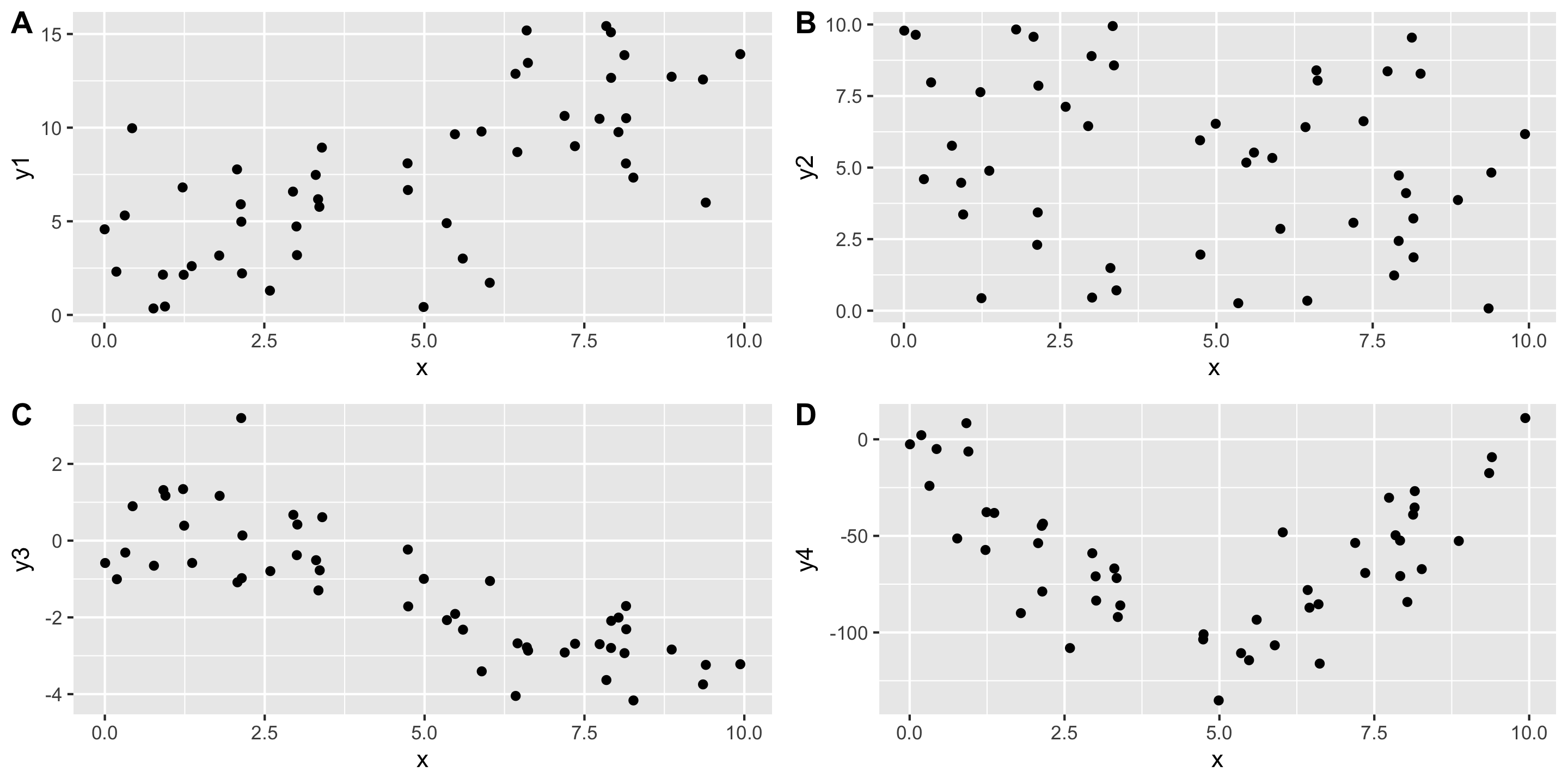
- Need a summary statistics that quantifies the strength and relationship of the linear trend!
Always graph the data when exploring relationships!
Simple Linear Regression
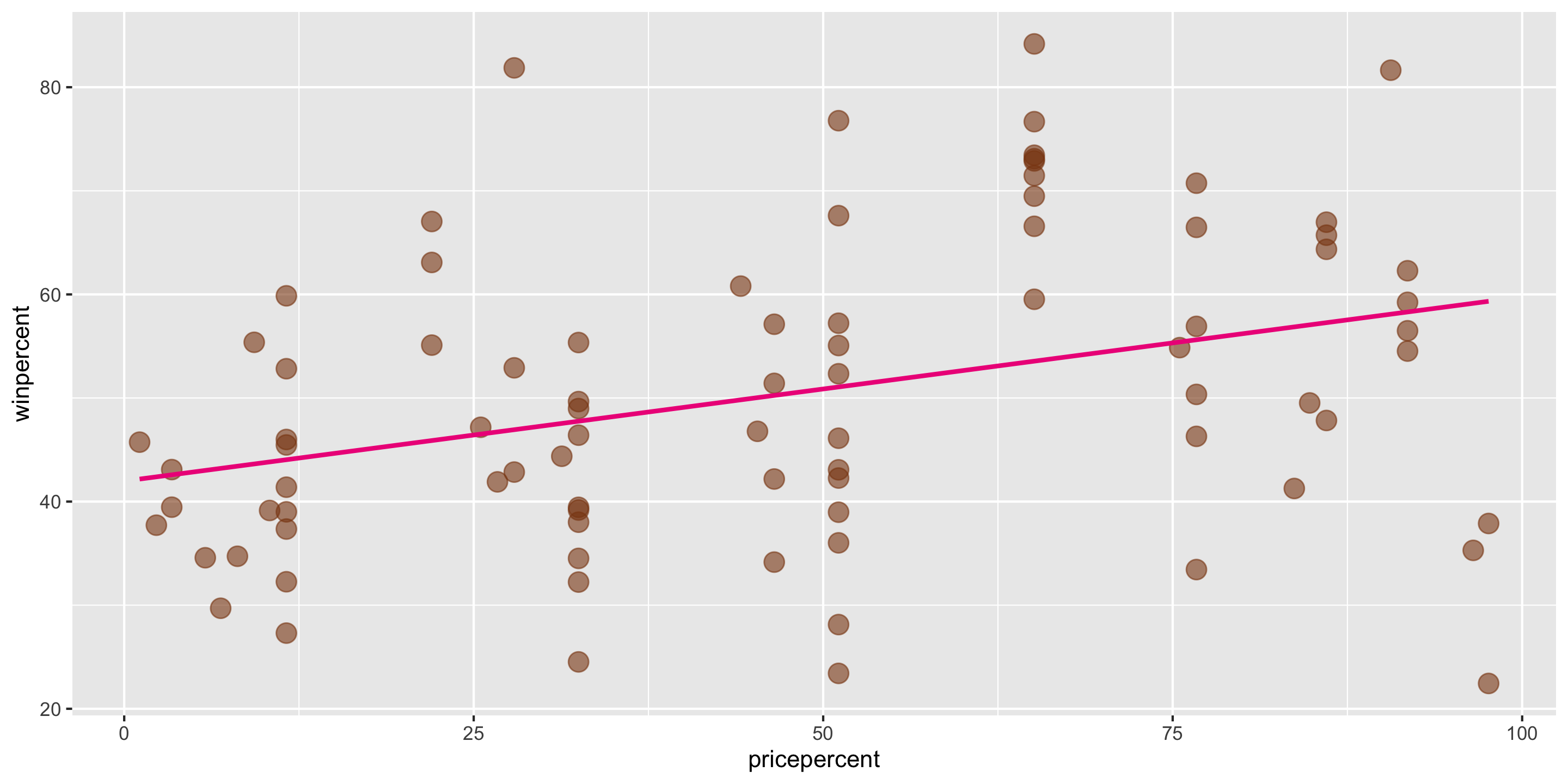
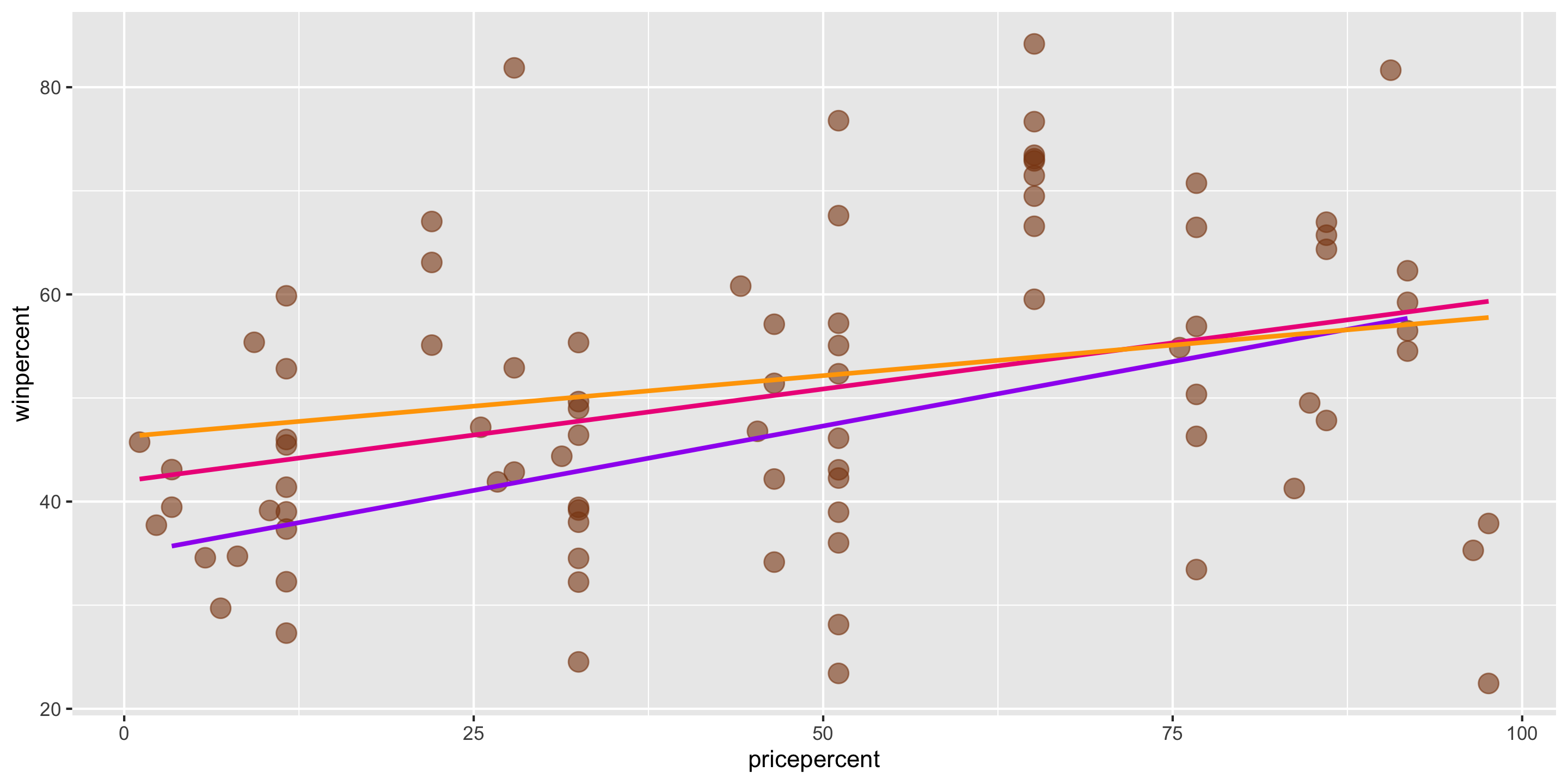
Let’s return to the Candy Example.
A line is a reasonable model form.
Where should the line be?
- Slope? Intercept?
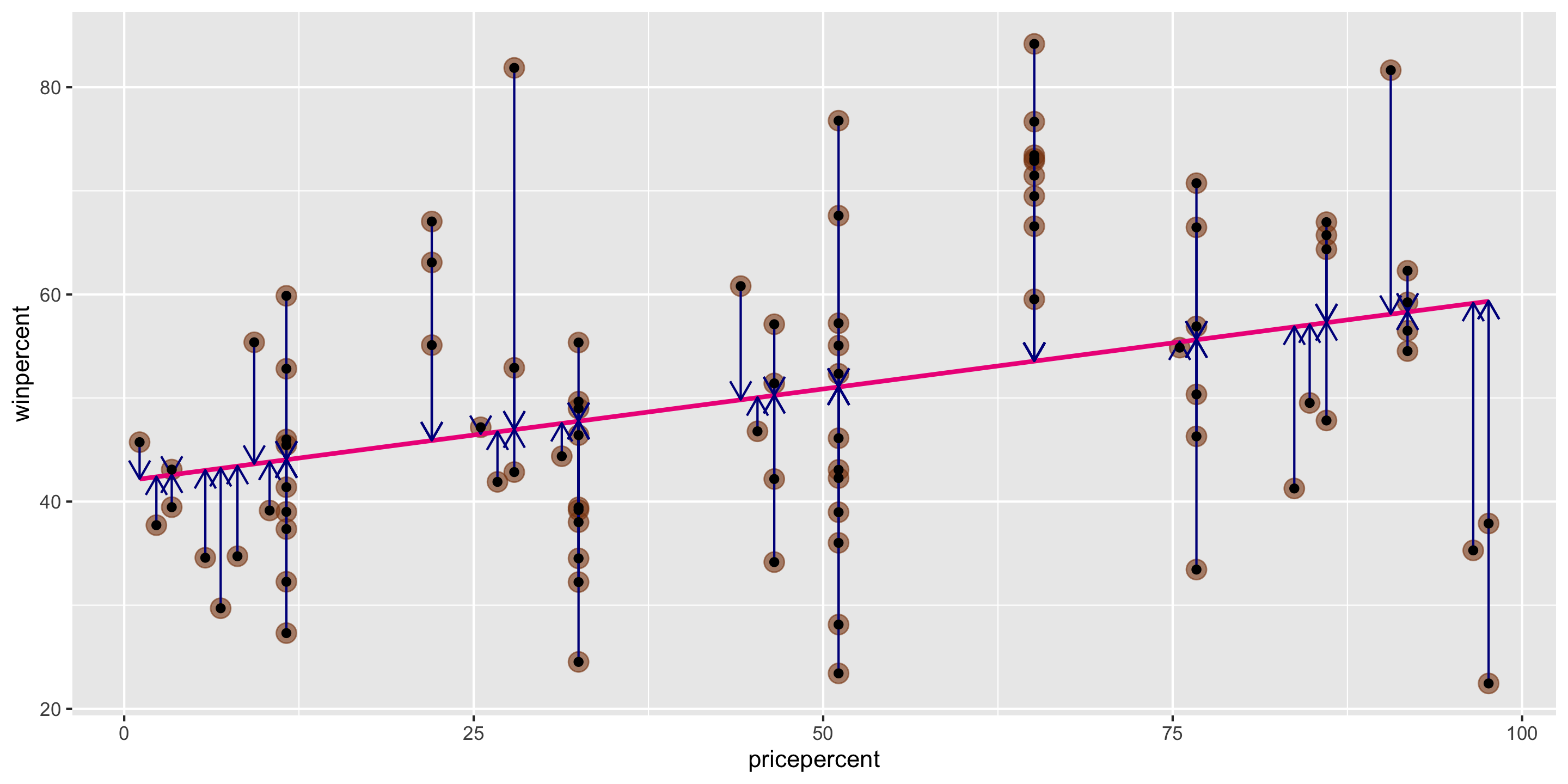
Method of Least Squares
Want residuals to be small.
Minimize a function of the residuals.
Minimize:
\[ \sum_{i = 1}^n e^2_i \]
Method of Least Squares
ggplot2 will compute the line and add it to your plot using geom_smooth(method = "lm")
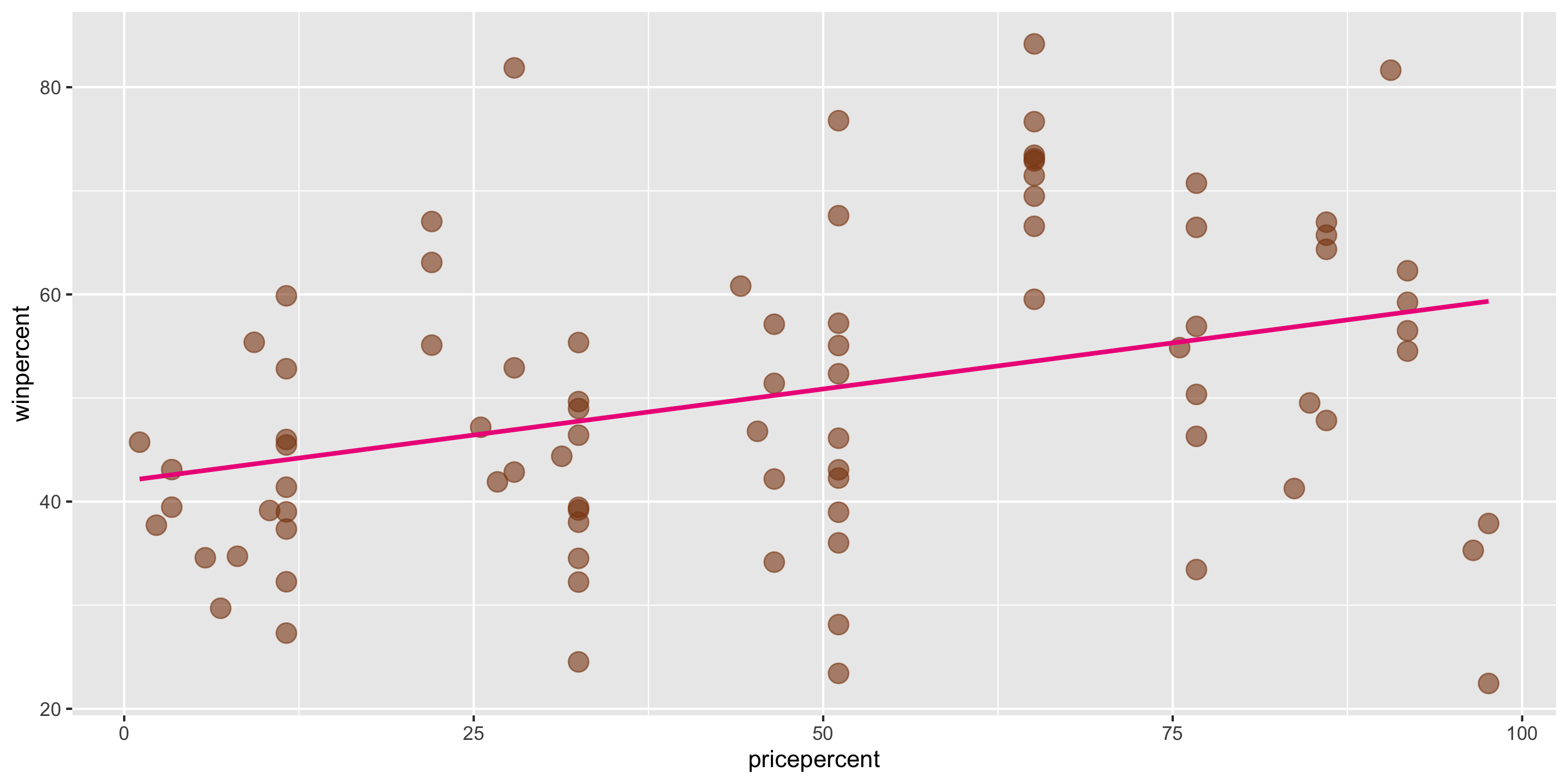
But what are the exact values of \(\hat{\beta}_o\) and \(\hat{\beta}_1\)?