Rows: 313
Columns: 16
$ Movie <chr> "Spider-Man 3", "Transformers", "Pirates of the Carib…
$ LeadStudio <chr> "Sony", "Paramount", "Disney", "Warner Bros", "Warner…
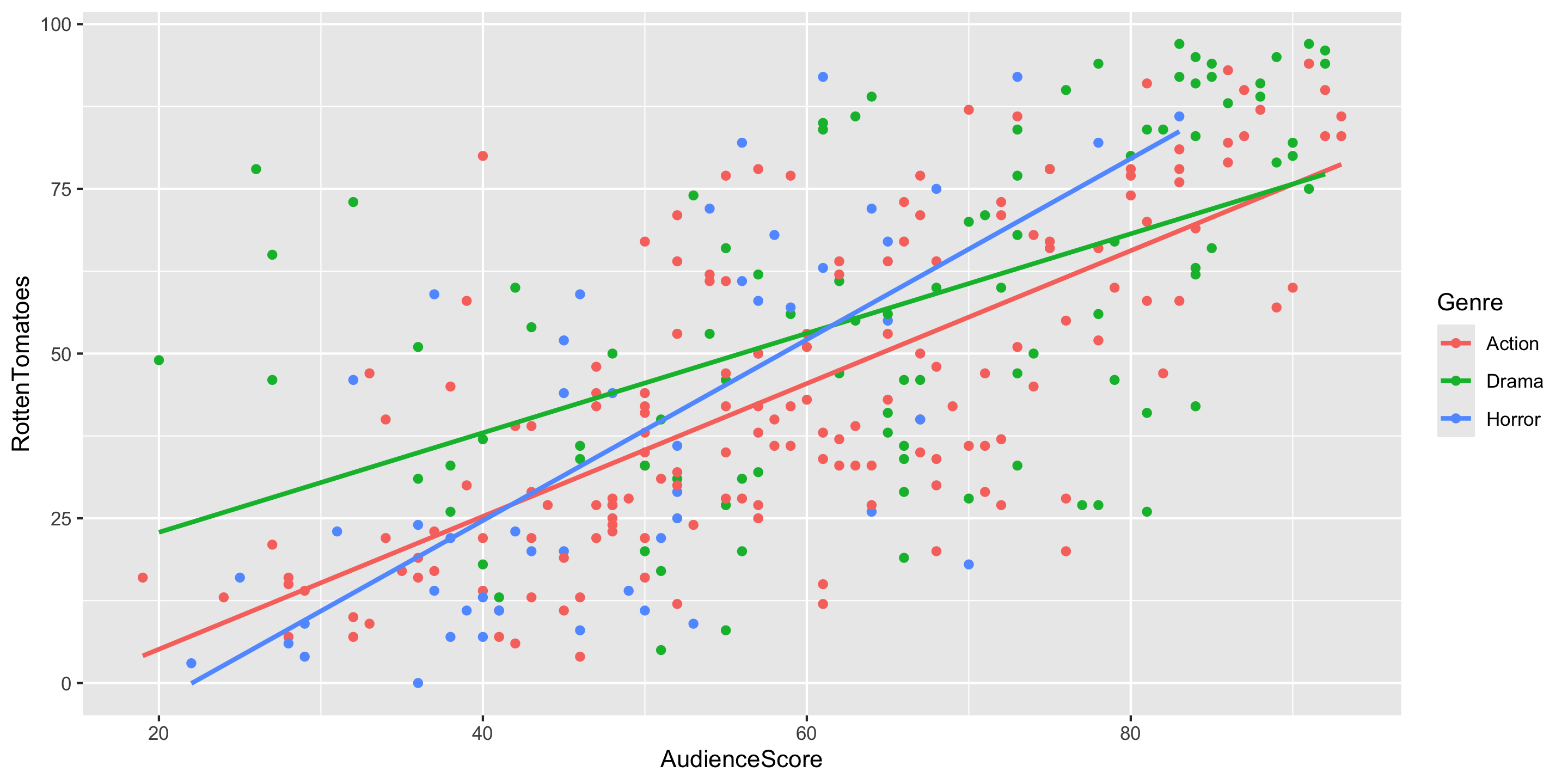
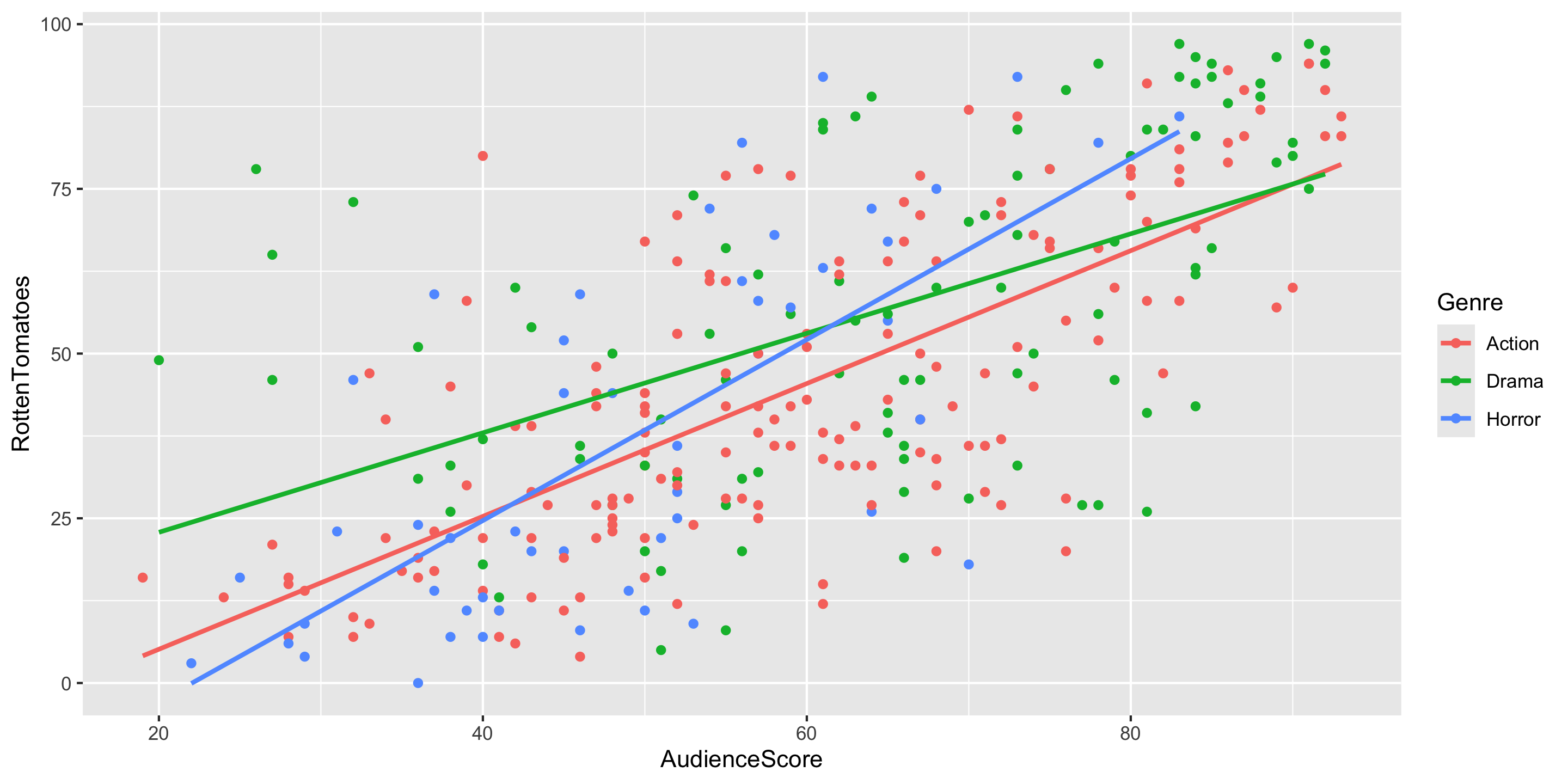
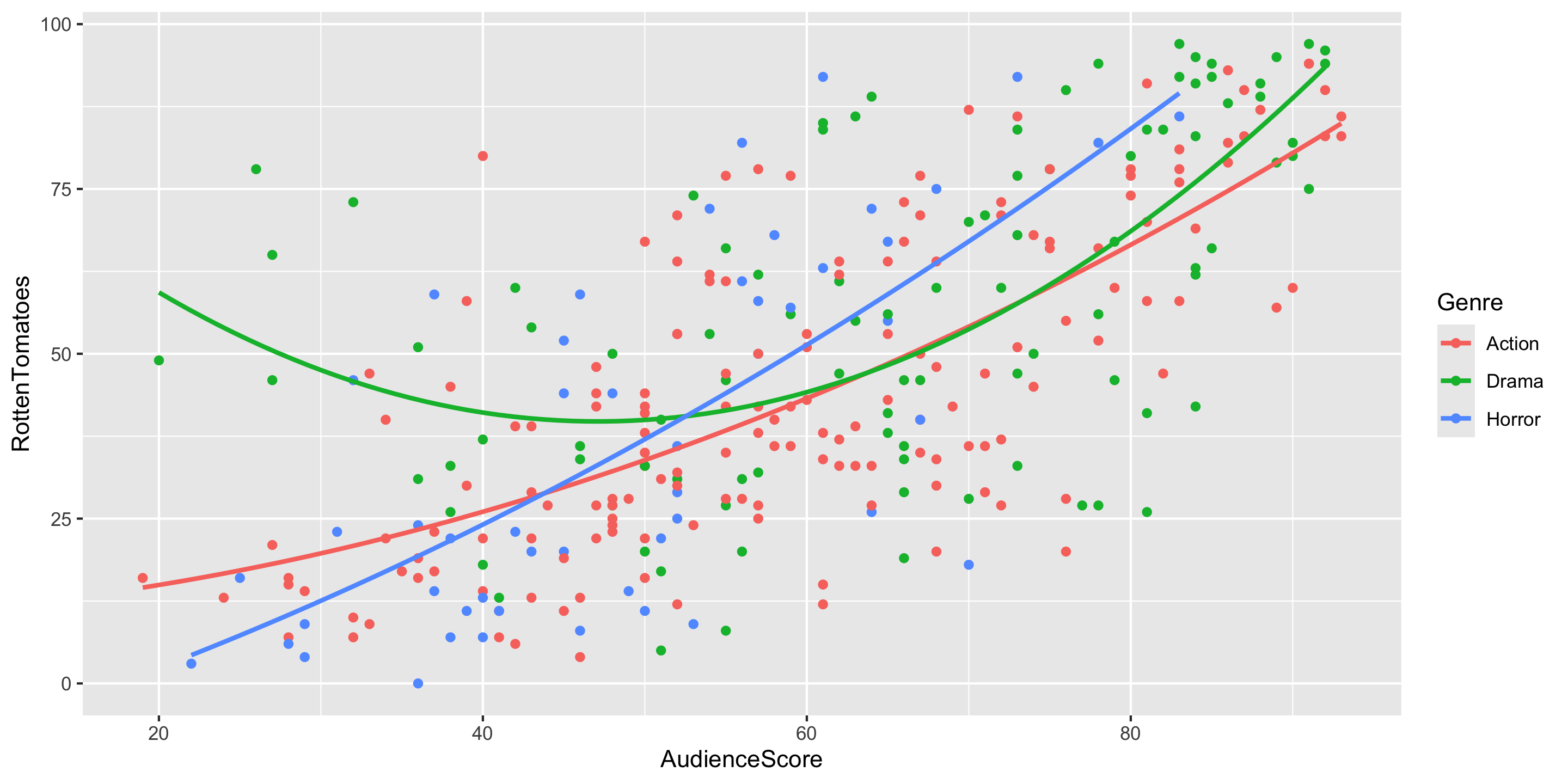
$ RottenTomatoes <dbl> 61, 57, 45, 60, 20, 79, 35, 28, 41, 71, 95, 42, 18, 2…
$ AudienceScore <dbl> 54, 89, 74, 90, 68, 86, 55, 56, 81, 52, 84, 55, 70, 6…
$ Story <chr> "Metamorphosis", "Monster Force", "Rescue", "Sacrific…
$ Genre <chr> "Action", "Action", "Action", "Action", "Action", "Ac…
$ TheatersOpenWeek <dbl> 4252, 4011, 4362, 3103, 3778, 3408, 3959, 3619, 2911,…
$ OpeningWeekend <dbl> 151.1, 70.5, 114.7, 70.9, 49.1, 33.4, 58.0, 45.3, 19.…
$ BOAvgOpenWeekend <dbl> 35540, 17577, 26302, 22844, 12996, 9791, 14663, 12541…
$ DomesticGross <dbl> 336.53, 319.25, 309.42, 210.61, 140.13, 134.53, 131.9…
$ ForeignGross <dbl> 554.34, 390.46, 654.00, 245.45, 117.90, 249.00, 157.1…
$ WorldGross <dbl> 890.87, 709.71, 963.42, 456.07, 258.02, 383.53, 289.0…
$ Budget <dbl> 258.0, 150.0, 300.0, 65.0, 140.0, 110.0, 130.0, 110.0…
$ Profitability <dbl> 345.30, 473.14, 321.14, 701.64, 184.30, 348.66, 222.3…
$ OpenProfit <dbl> 58.57, 47.00, 38.23, 109.08, 35.07, 30.36, 44.62, 41.…
$ Year <dbl> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007,…