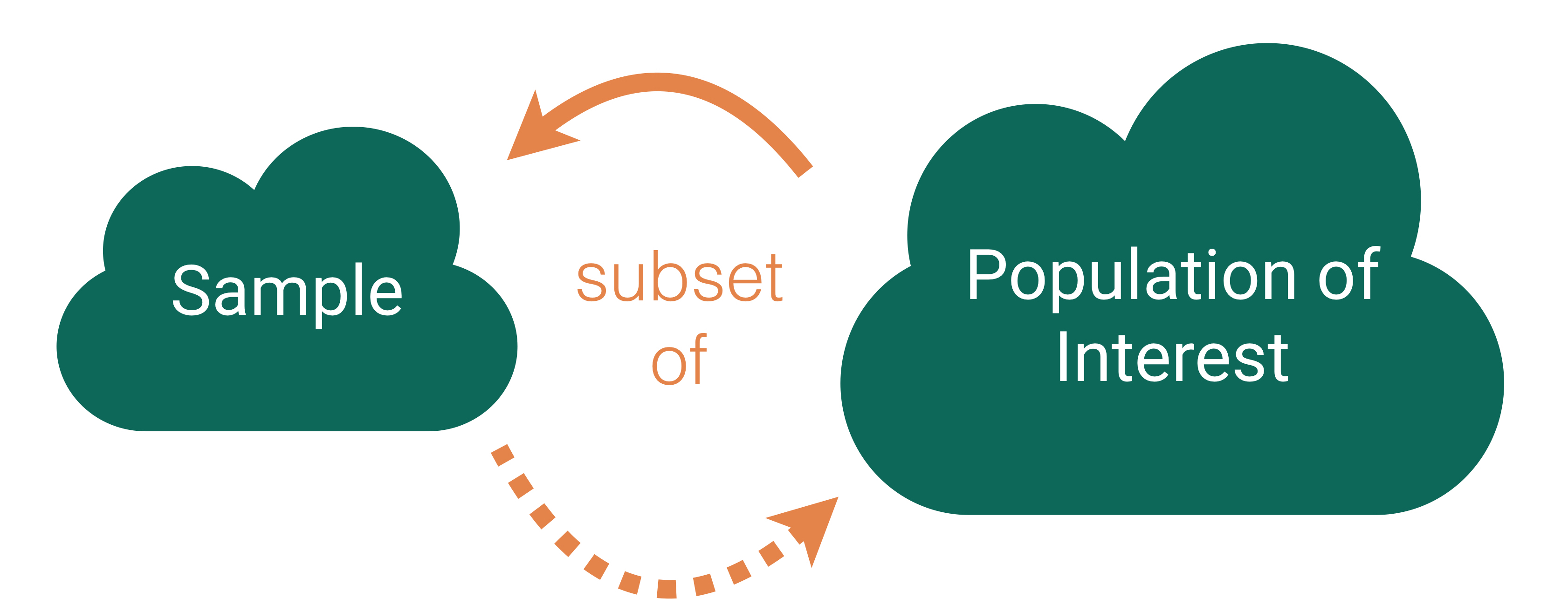
Like with regression, need to distinguish between the population and the sample
Parameters:
Based on the population
Unknown then if don’t have data on the whole population
EX: \(\beta_o\) and \(\beta_1\)
EX: \(\mu\) = population mean
Statistics:
Based on the sample data
Known
Usually estimate a population parameter
EX: \(\hat{\beta}_o\) and \(\hat{\beta}_1\)
EX: \(\bar{x}\) = sample mean
Statistical Inference
Goal: Draw conclusions about the population based on the sample.
Plato’s allegory of the cave
Statistical Inference
Goal: Draw conclusions about the population based on the sample.
Main Flavors
Estimating numerical quantities (parameters).
Testing conjectures.
Estimation
Goal: Estimate a (population) parameter.
Best guess?
The corresponding (sample) statistic
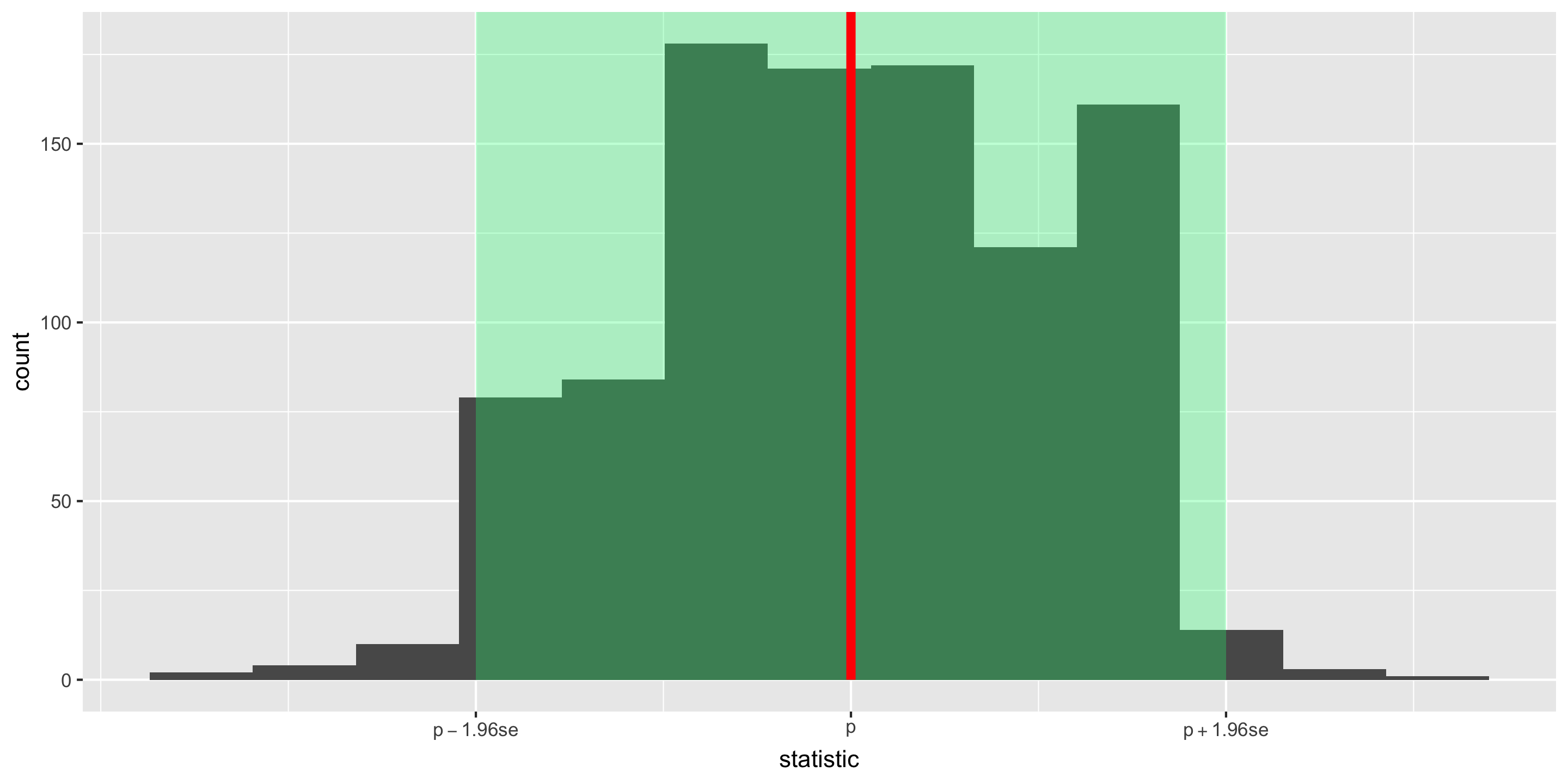
Key Question: How accurate is the statistic as an estimate of the parameter?
Helpful Sub-Question: If we take many samples, how much would the statistic vary from sample to sample?
Need two new concepts:
The sampling variability of a statistic
The sampling distribution of a statistic
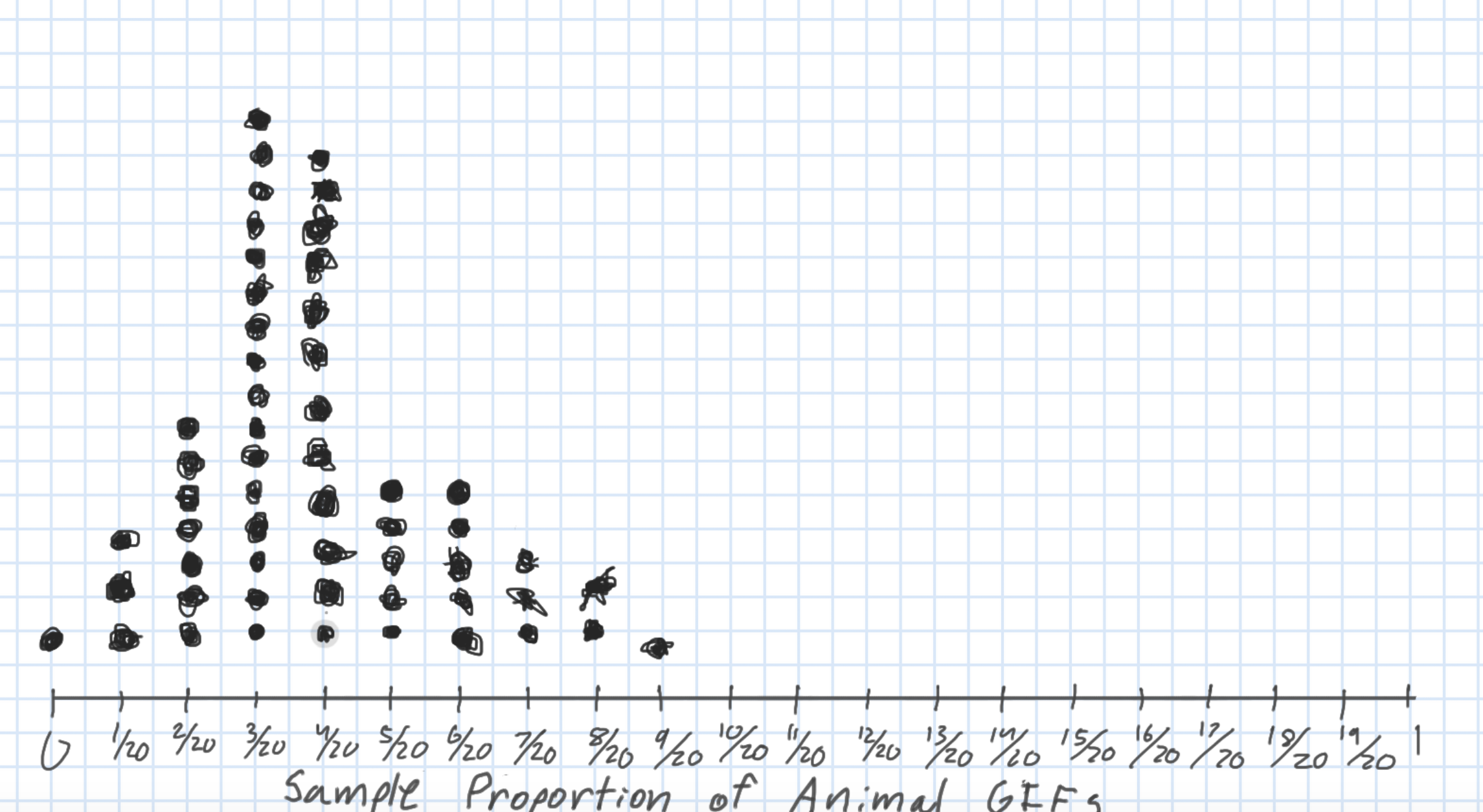
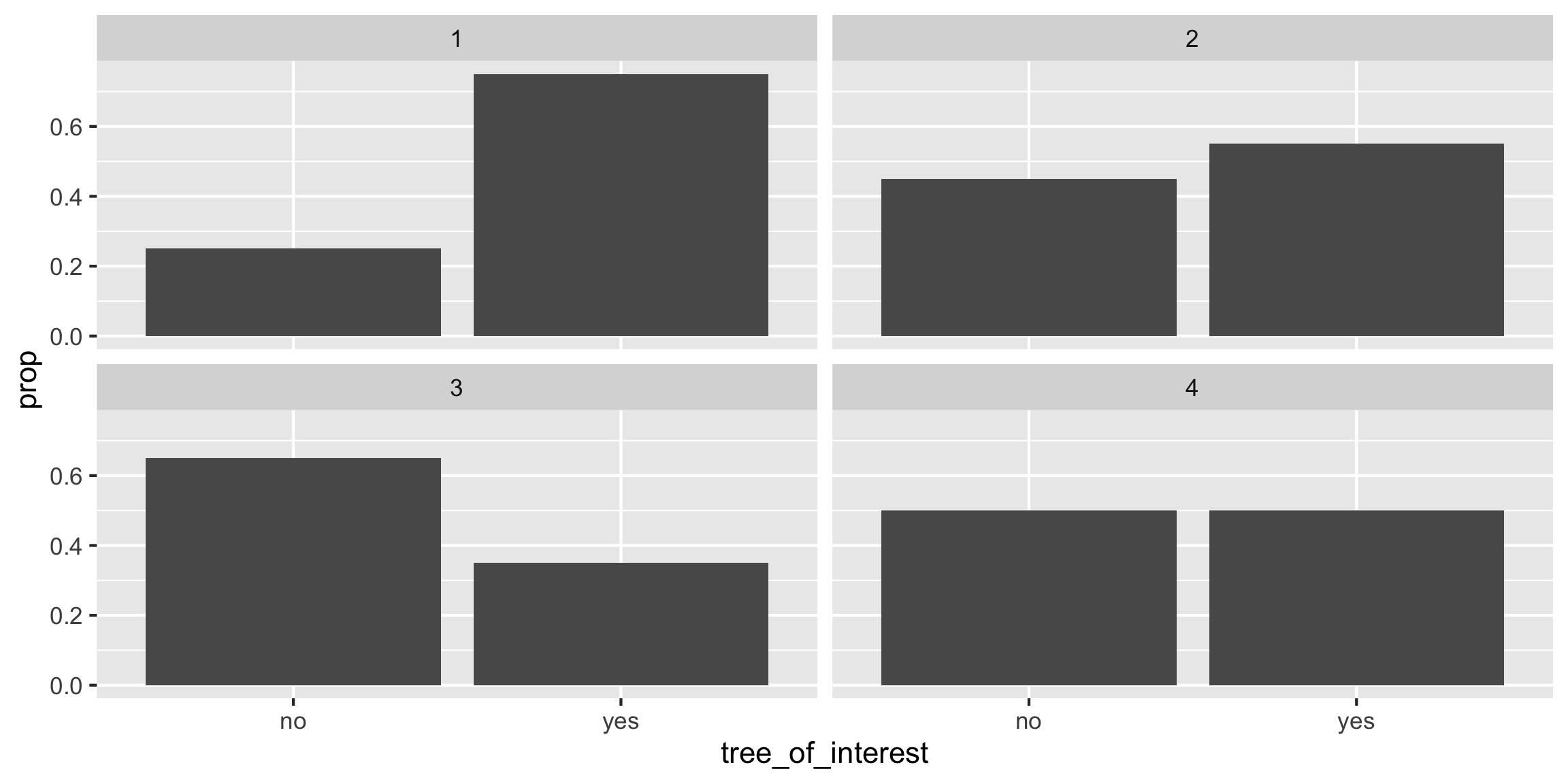
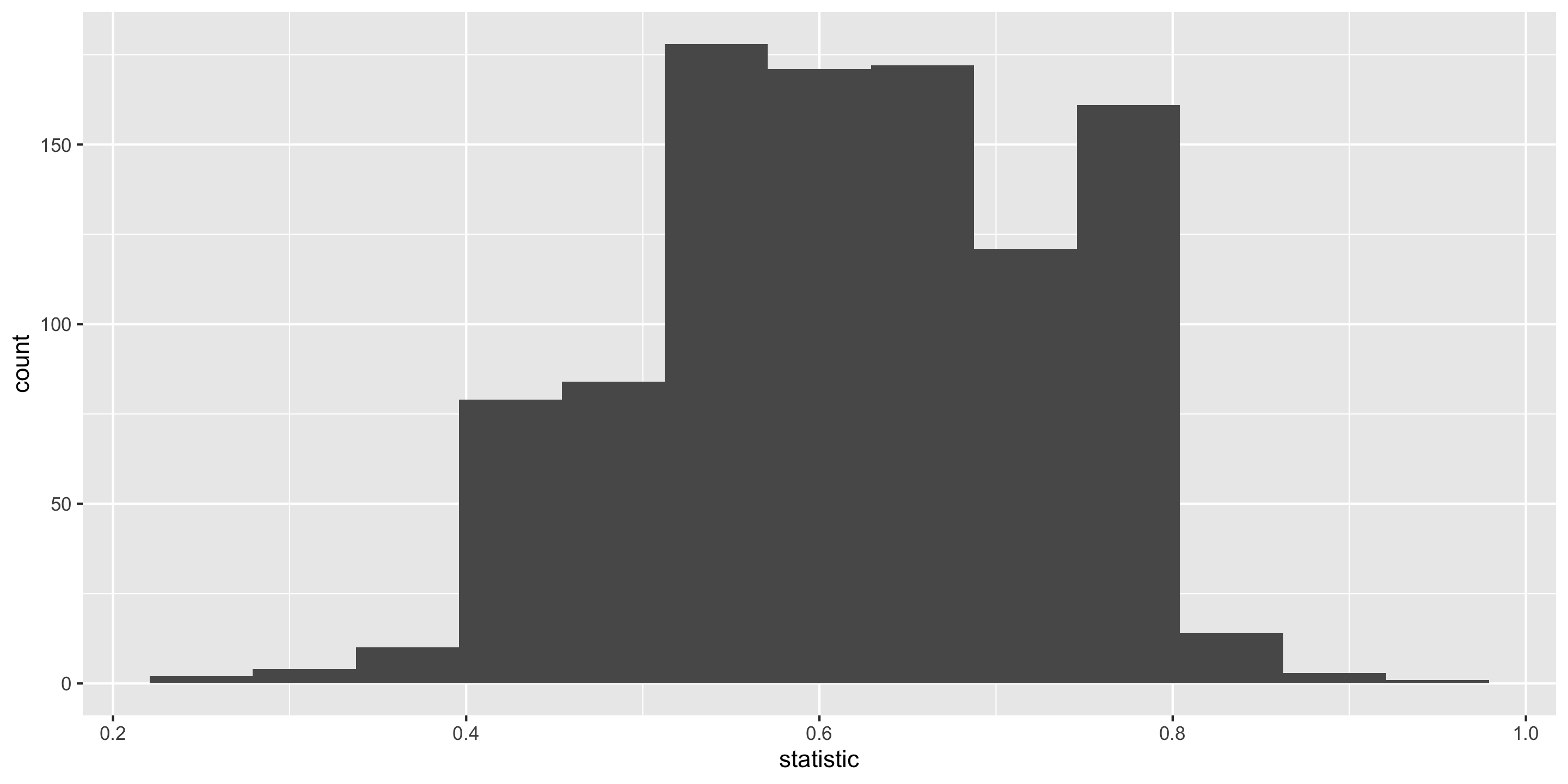
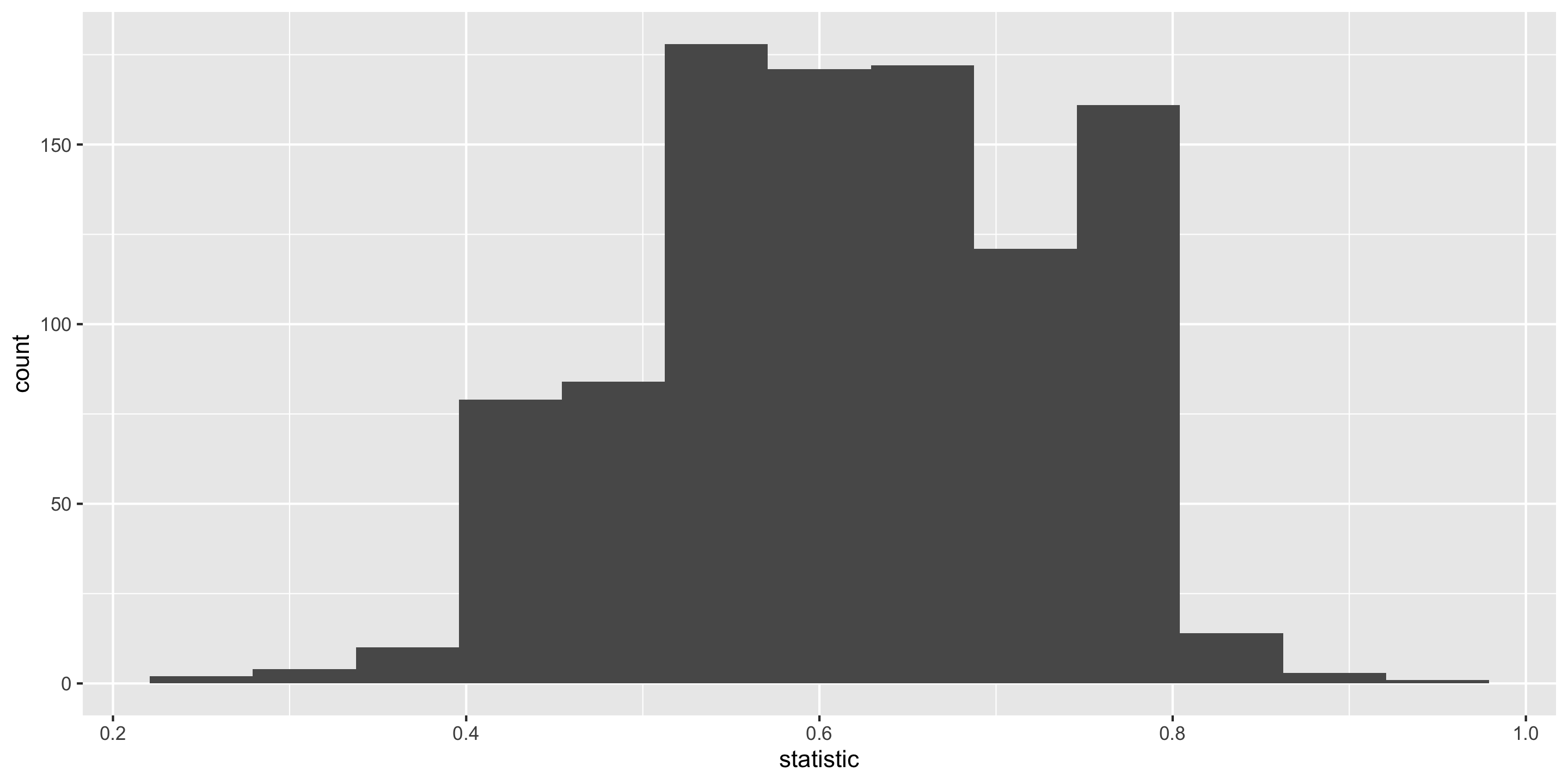
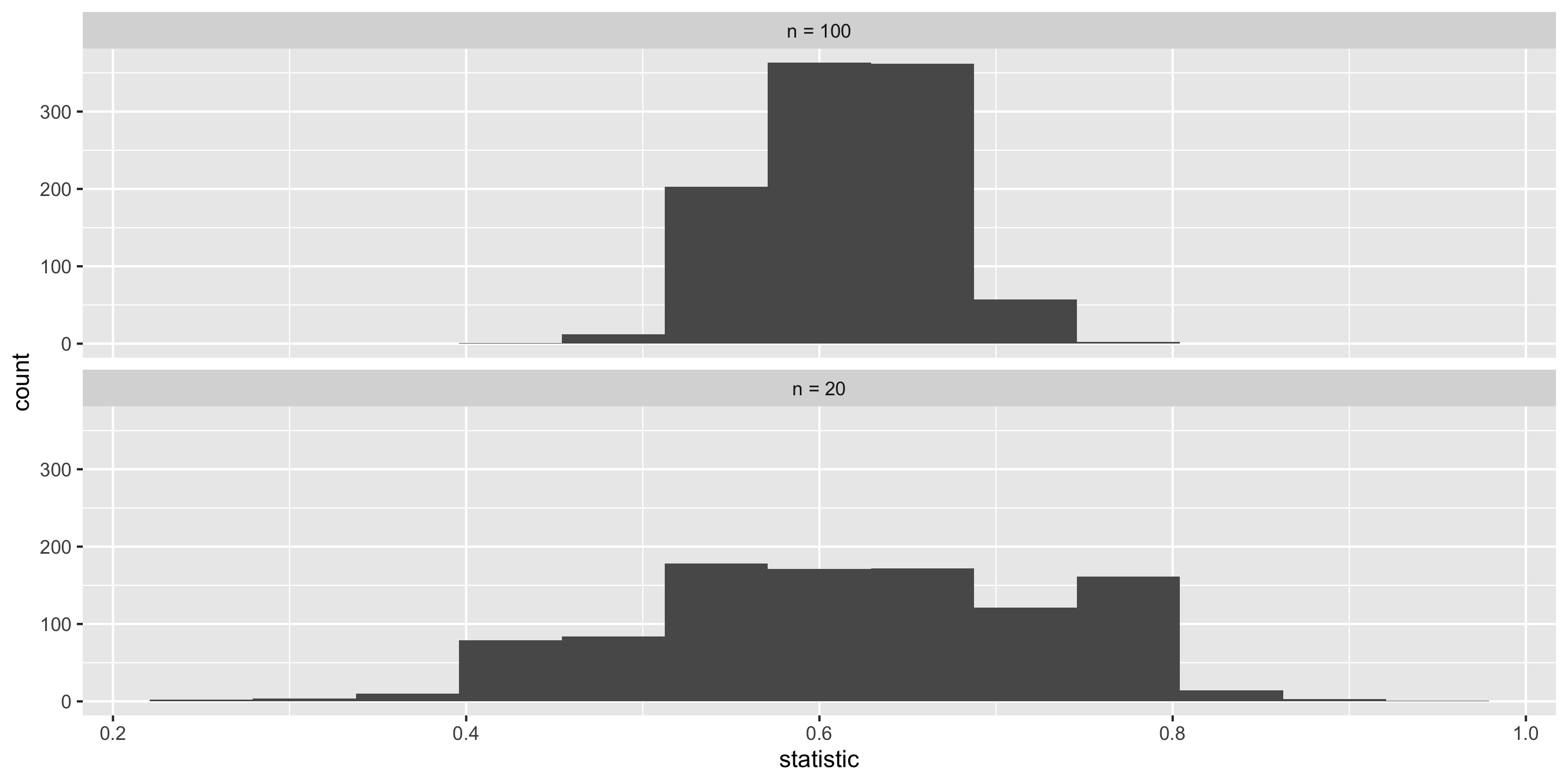
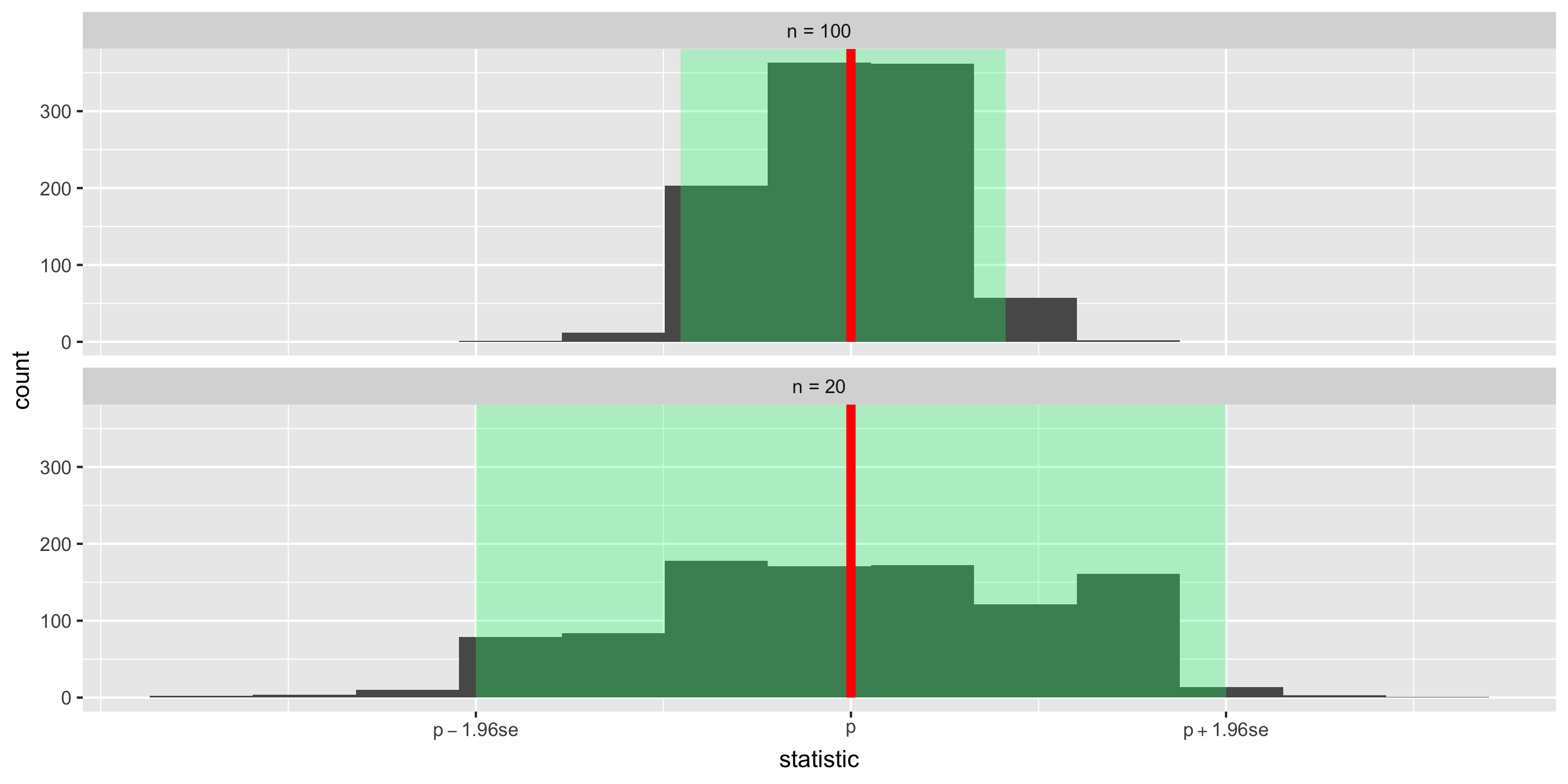
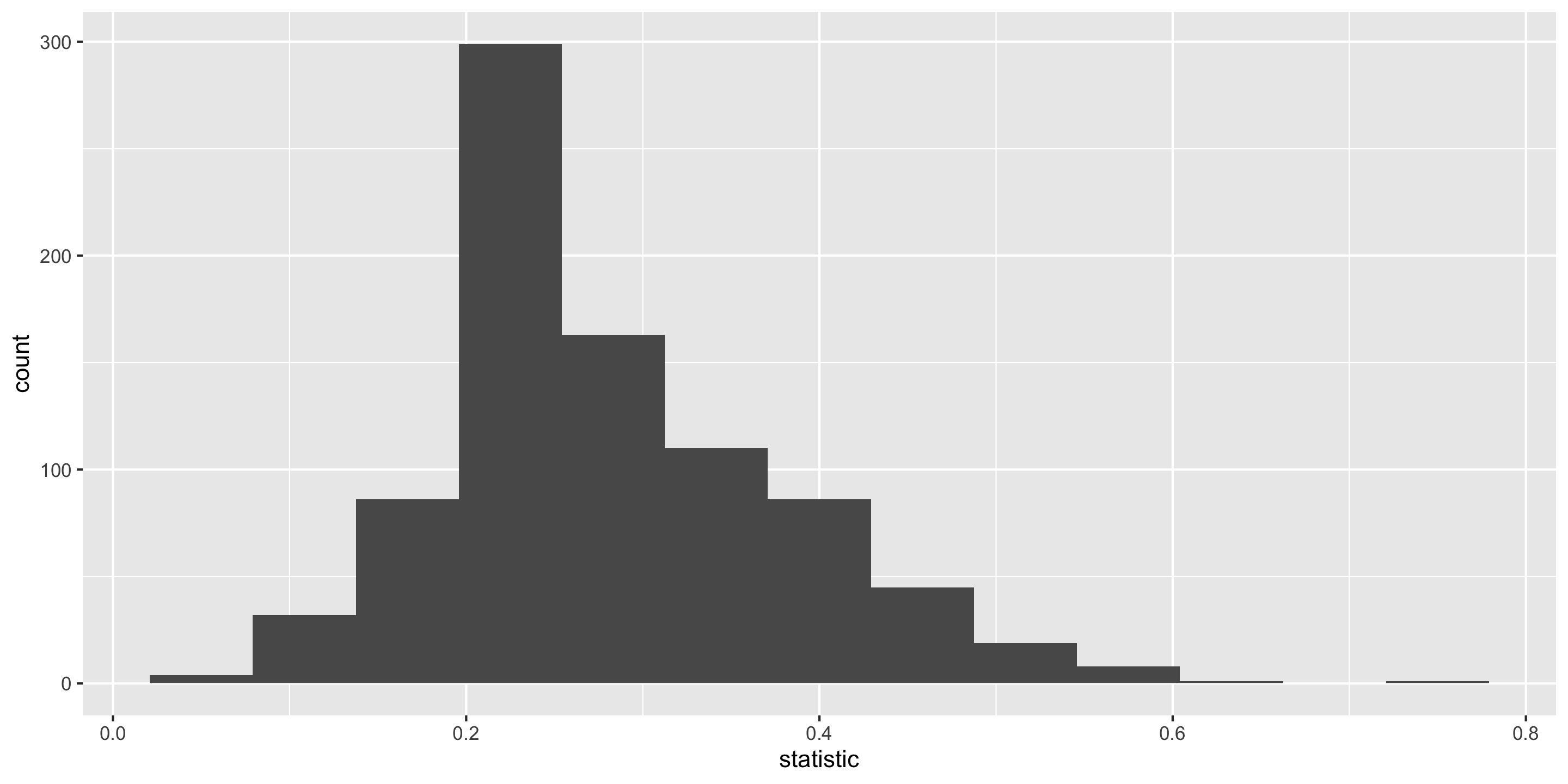
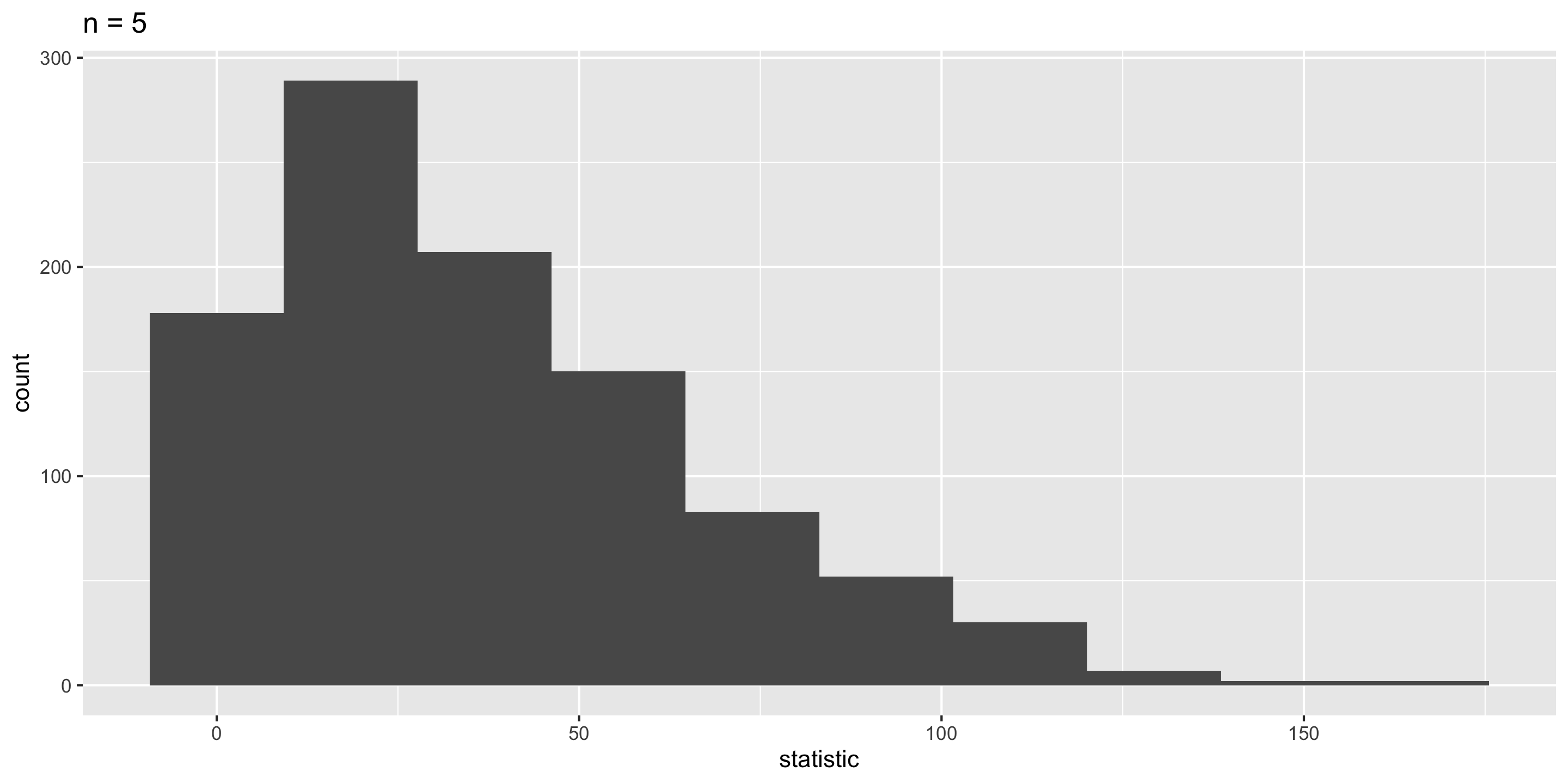
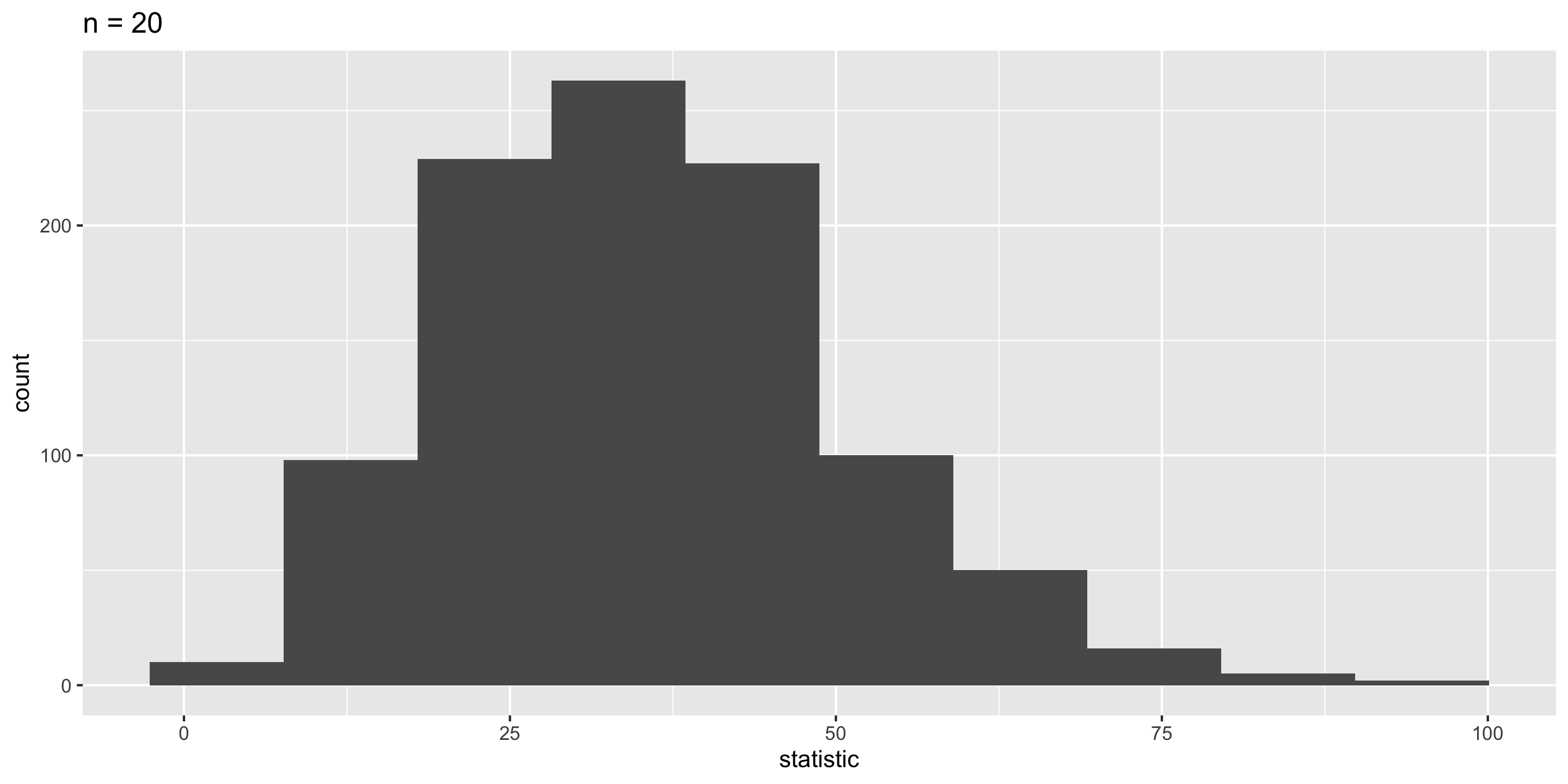
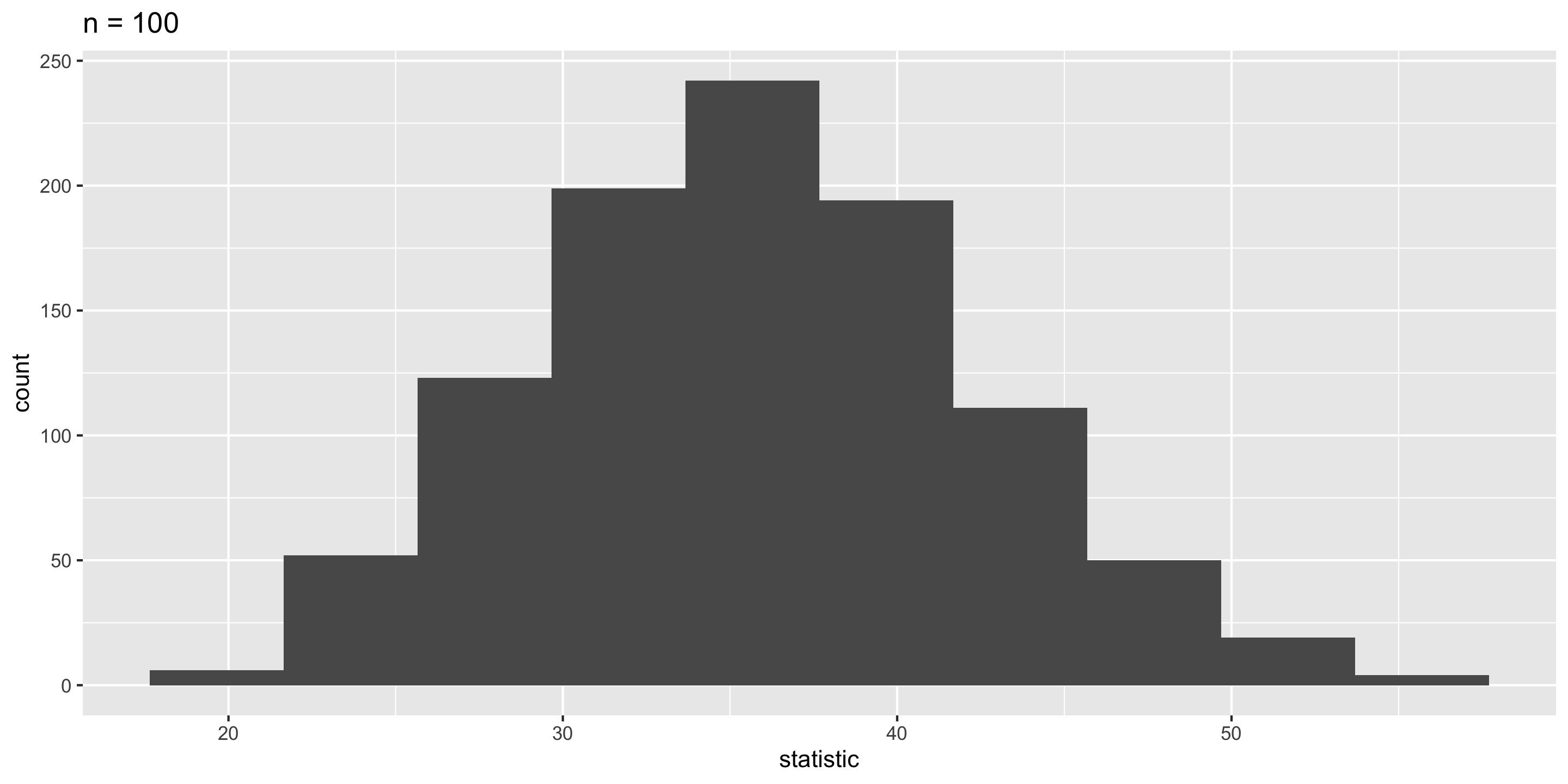
Sampling Distribution of a Statistic
Steps to Construct an (Approximate) Sampling Distribution:
Decide on a sample size, \(n\).
Randomly select a sample of size \(n\) from the population.
Compute the sample statistic.
Put the sample back in.
Repeat Steps 2 - 4 many (1000+) times.
Sampling Distribution of a Statistic
Center? Shape?
Spread?
Standard error = standard deviation of the statistic
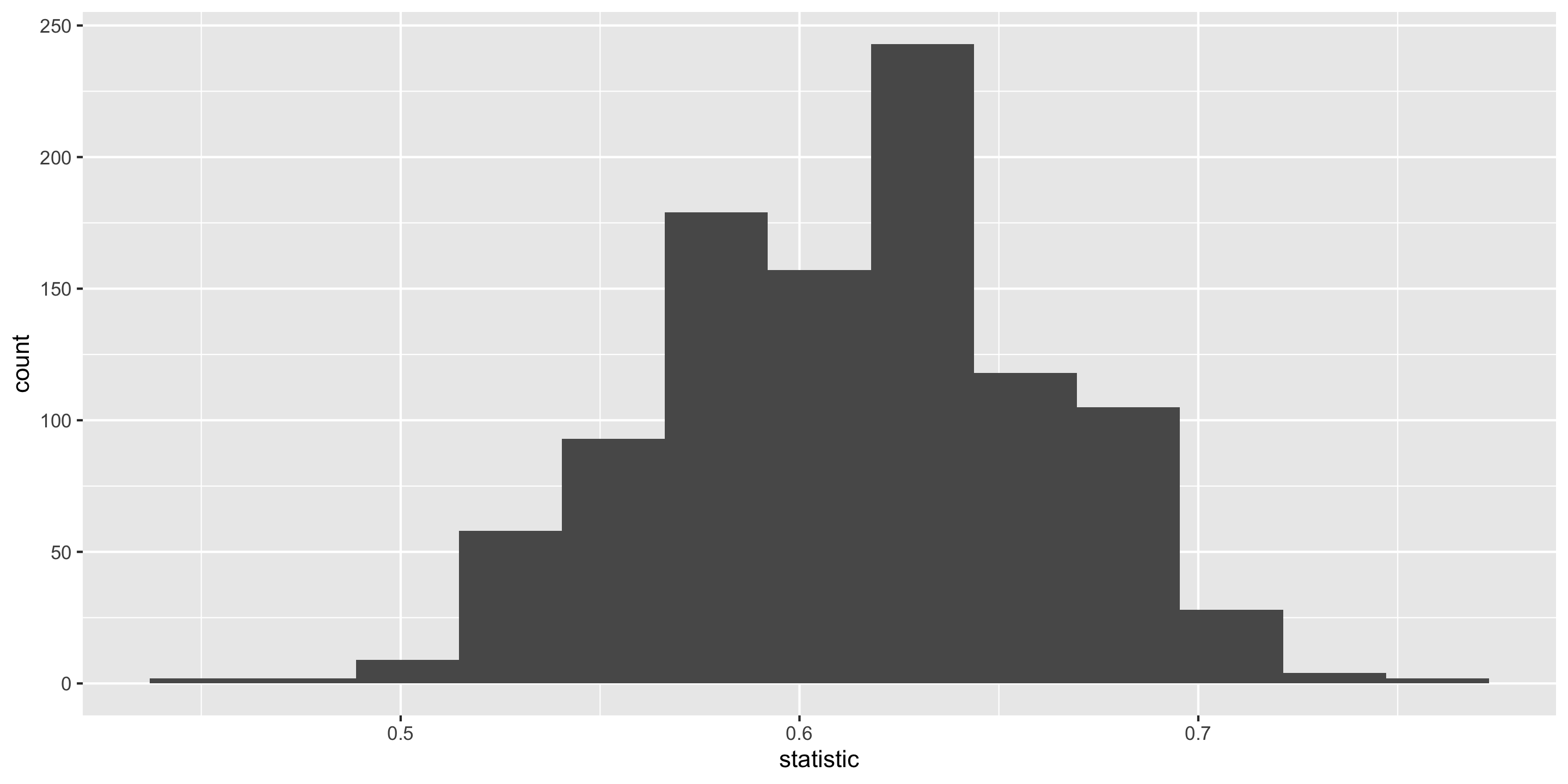
What happens to the center/spread/shape as we increase the sample size?
What happens to the center/spread/shape if the true parameter changes?
Let’s Construct Some Sampling Distributions using R!
Important Notes
To construct a sampling distribution for a statistic, we need access to the entire population so that we can take repeated samples from the population.
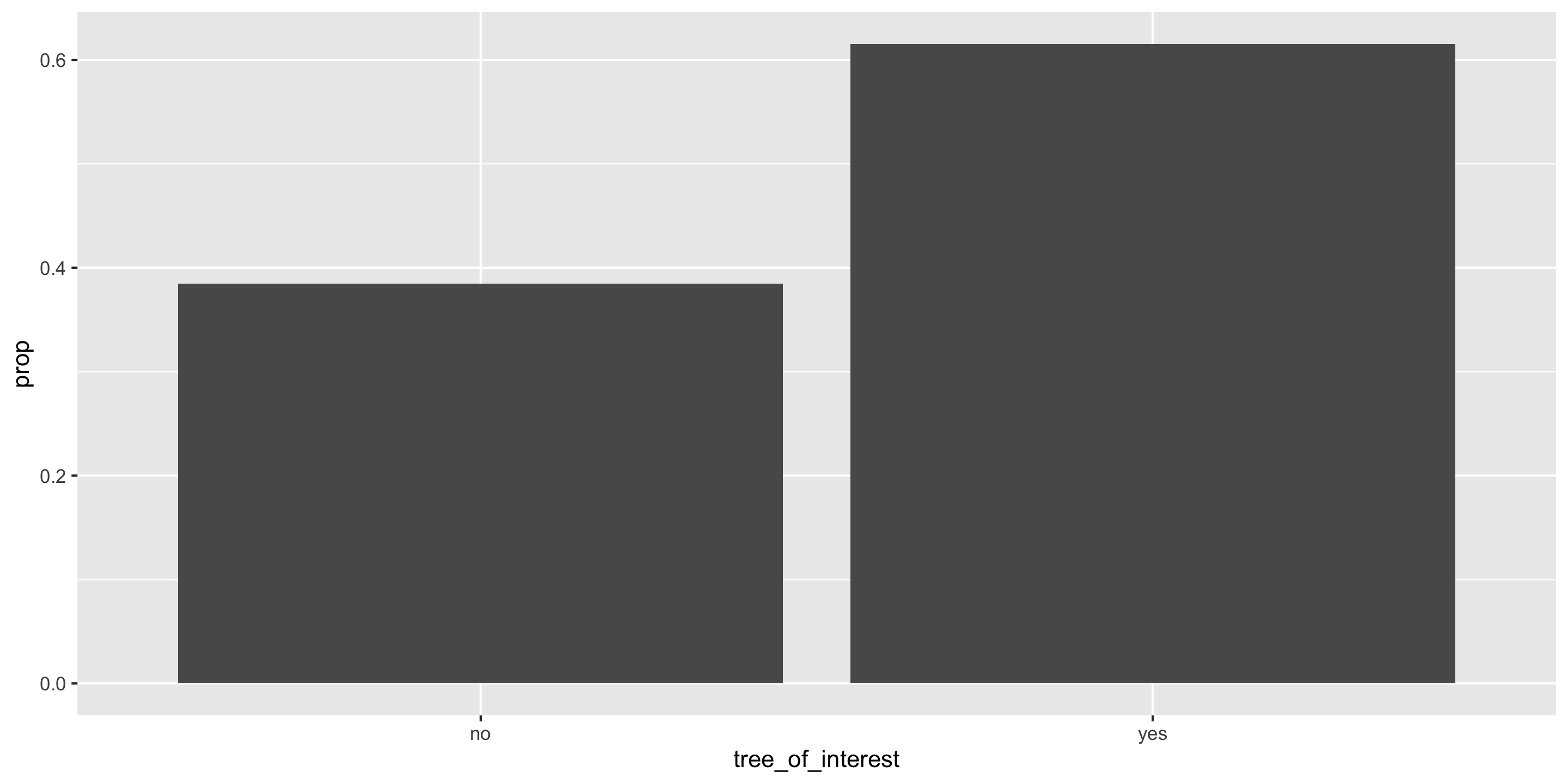
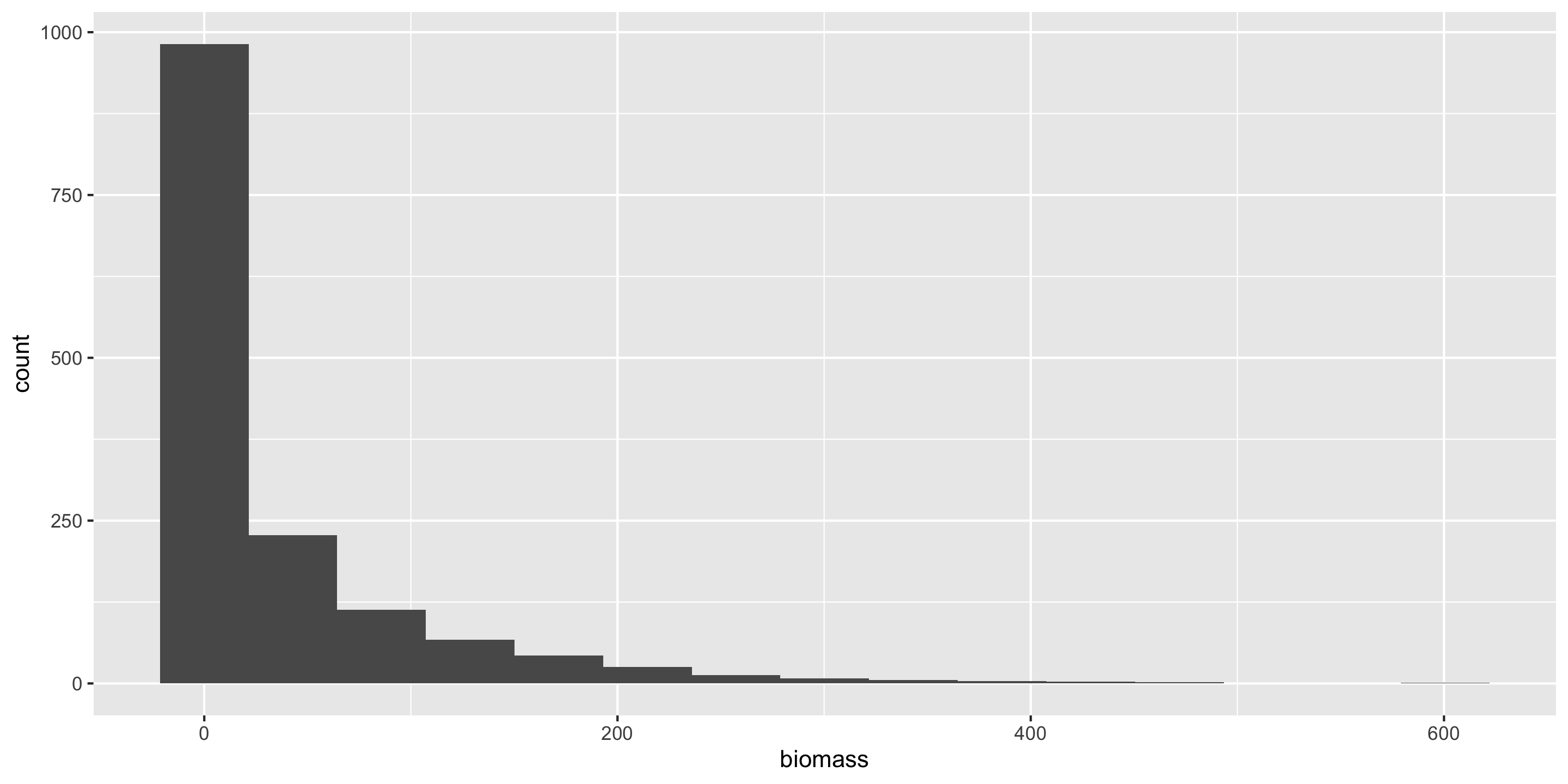
Population = Mt Tabor trees
But if we have access to the entire population, then we know the value of the population parameter.
Can compute the exact proportion of maple trees in our population.
The sampling distribution is needed in the exact scenario where we can’t compute it: the scenario where we only have a single sample.
We will learn how to estimate the sampling distribution soon.
Today, we have the entire population and are constructing sampling distributions anyway to study their properties!