It is time to move beyond just point estimates to interval estimates that quantify our uncertainty.
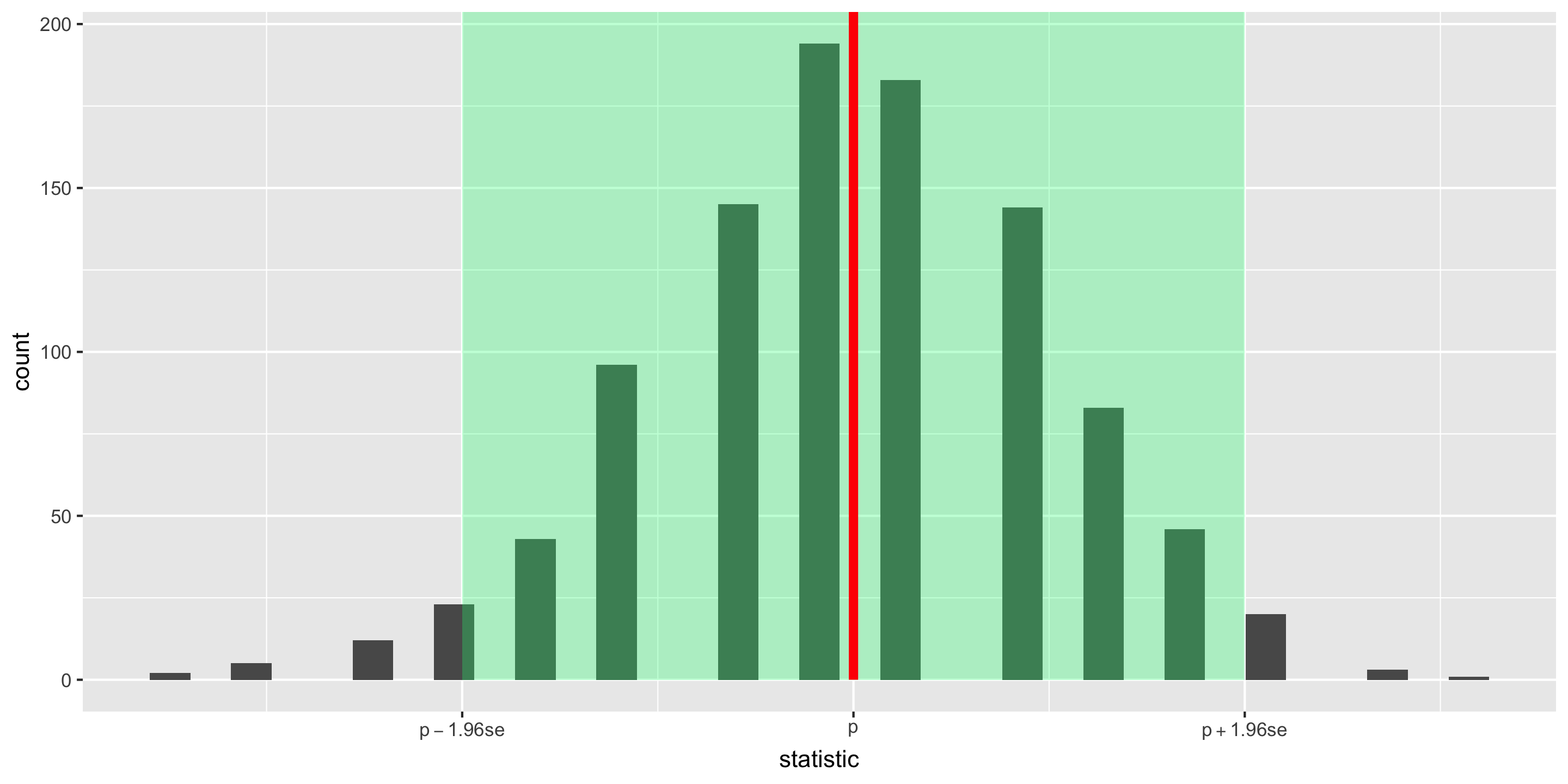
We saw that 95% of all samples fell within 1.96 standard errors from the center of the (approximate) sampling distribution.
Confidence Intervals
It is time to move beyond just point estimates to interval estimates that quantify our uncertainty.
This quite naturally introduces us to the idea of confidence intervals:
Confidence Interval: Interval of plausible values for a parameter
Form: \(\mbox{statistic} \pm \mbox{Margin of Error}\)
Question: How do we find the Margin of Error (ME)?
Answer: If the sampling distribution of the statistic is approximately bell-shaped and symmetric, then a statistic will be within 1.96 SEs of the parameter for 95% of the samples.
Called a 95% confidence interval (CI). (Will discuss the meaning of confidence soon)
Confidence Intervals
95% CI Form:
\[
\mbox{statistic} \pm 1.96\times\mbox{SE}
\]
It is easy to compute a statistic for the form above (sample proportion, sample mean, …)
But… What else do we need to construct the CI?
Problem: To compute the SE, we need many samples from the population. We have 1 sample.
Solution: Approximate the sampling distribution using ONLY OUR ONE SAMPLE!
Bootstrapping
The term bootstrapping refers to the phrase “to pull oneself up by one’s bootstraps”
The phrase originated in the 19th century as reference to a ludicrous or impossible feat
By the mid 20th century, its meaning had changed to suggest a success by one’s own efforts, without outside help (the “American Dream” myth)
Its use in statistics (dating from 1979) alludes to both interpretations.
The Impossible Task:
How can we learn about the sampling distribution, if we only have 1 sample?
The “Ludicrous” Solution obtained without outside help:
Draw repeated samples from the original sample at hand; compute the statistic of interest for each; plot the resulting distribution
Bootstraping: Algorithm
How do we approximate the sampling distribution?
Bootstrap Distribution of a Sample Statistic:
Take a sample of size \(n\)with replacement from the sample. Called a bootstrap sample.
Compute the statistic on the bootstrap sample.
Repeat 1 and 2 many (1000+) times.
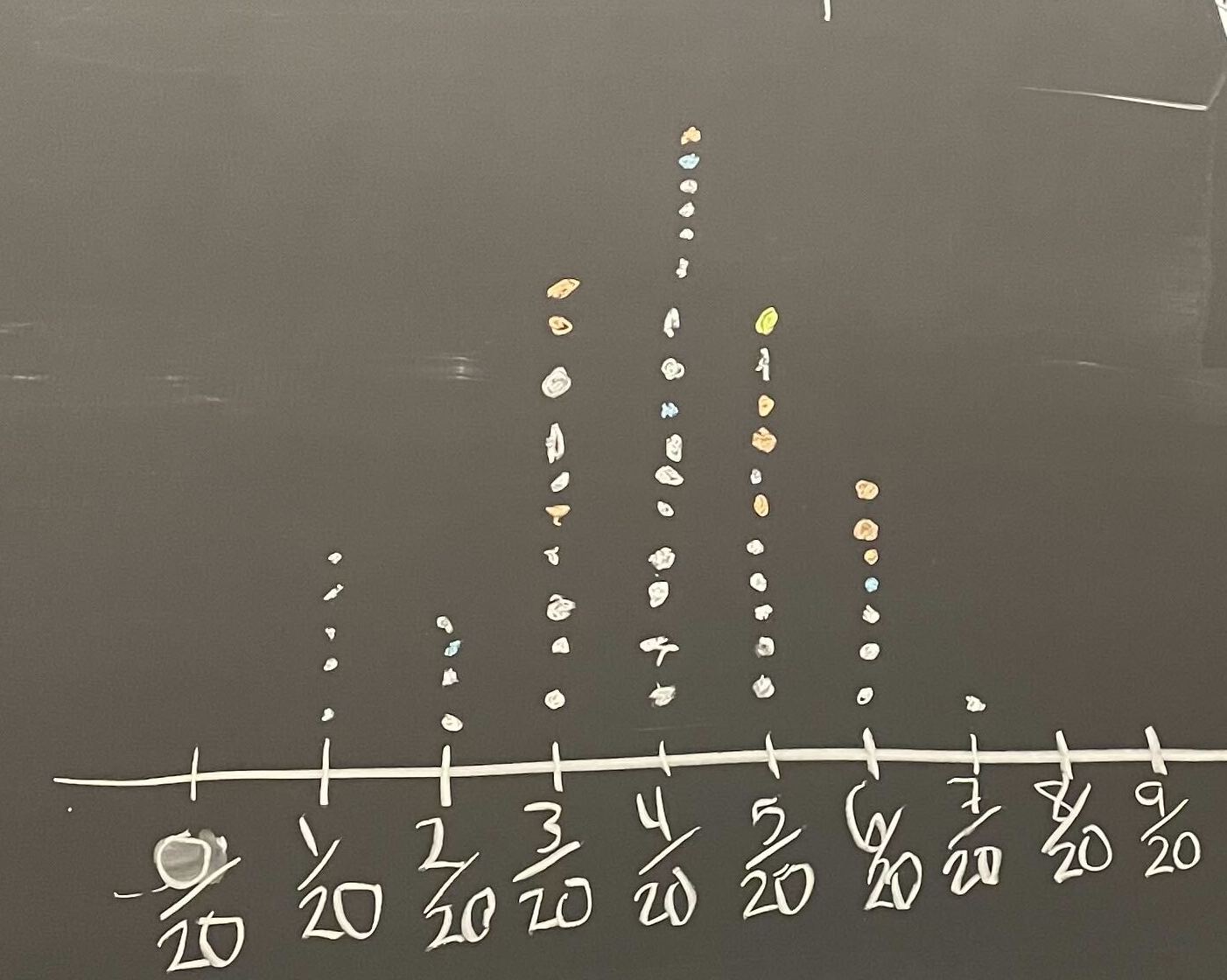
Let’s Practice Generating Bootstrap Samples!
Example: In a recent study, 23 rats showed compassion that surprised scientists. Twenty-three of the 30 rats in the study freed another trapped rat in their cage, even when chocolate served as a distraction and even when the rats would then have to share the chocolate with their freed companion. (Rats, it turns out, love chocolate.) Rats did not open the cage when it was empty or when there was a stuffed animal inside, only when a fellow rat was trapped. We wish to use the sample to estimate the proportion of rats that show empathy in this way.
Parameter:
Statistic:
Use your 30 cards to take a bootstrap sample. (Make sure to appropriately label them first!)
Compute the bootstrap statistic and put it on the class dotplot.
Sampling Distribution Versus Bootstrap Distribution
Data needed:
Center:
Spread:
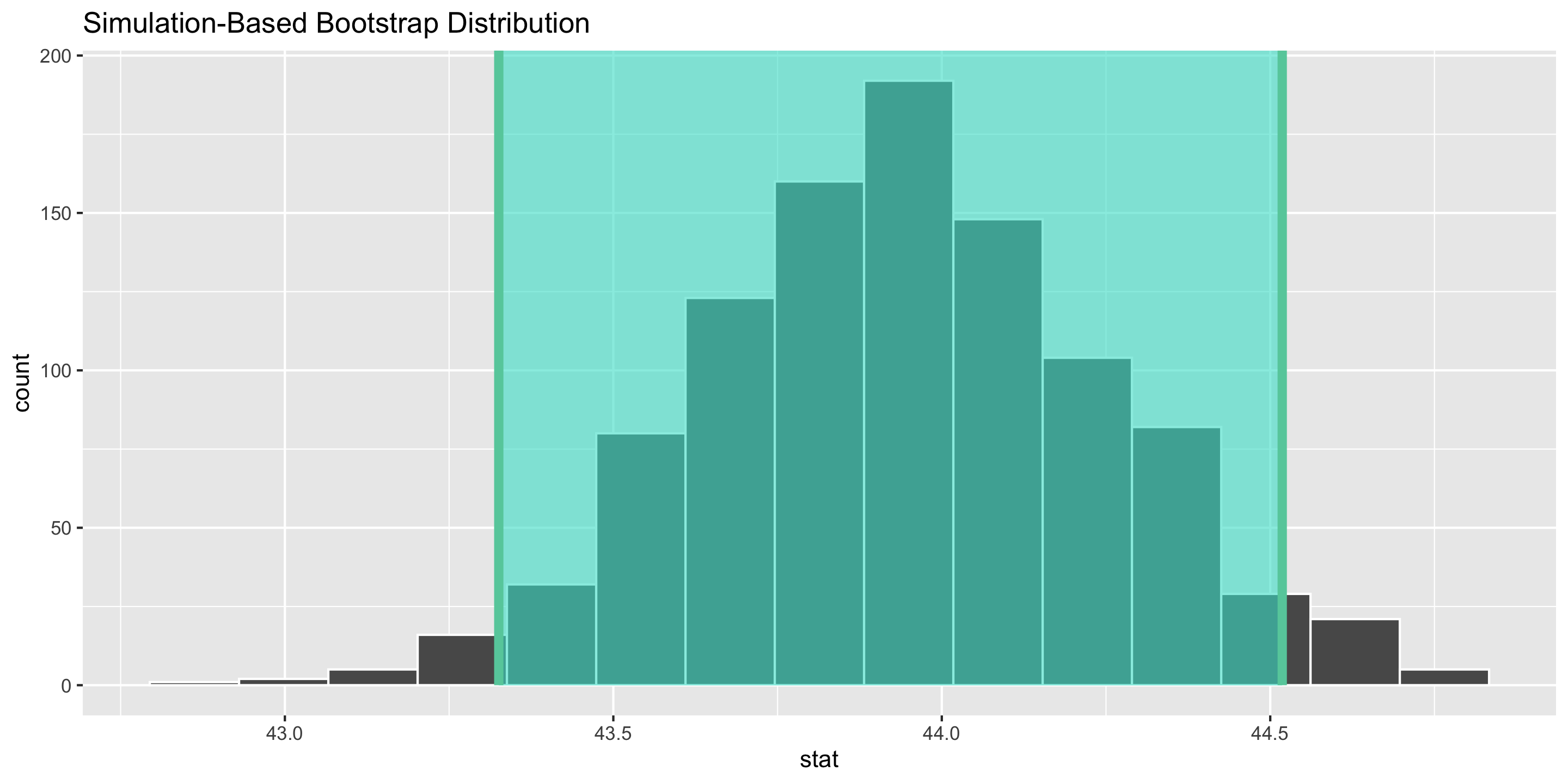
(Bootstrapped) Confidence Intervals
95% CI Form:
\[
\mbox{statistic} \pm 1.96 \times\mbox{SE}
\]
We approximate \(\mbox{SE}\) with \(\widehat{\mbox{SE}}\) = the standard deviation of the bootstrapped statistics.
Caveats:
Assuming a random sample
Even with random samples, sometimes we get non-representative samples. Bootstrapping can’t fix that.
Assuming the bootstrap distribution is bell-shaped and symmetric
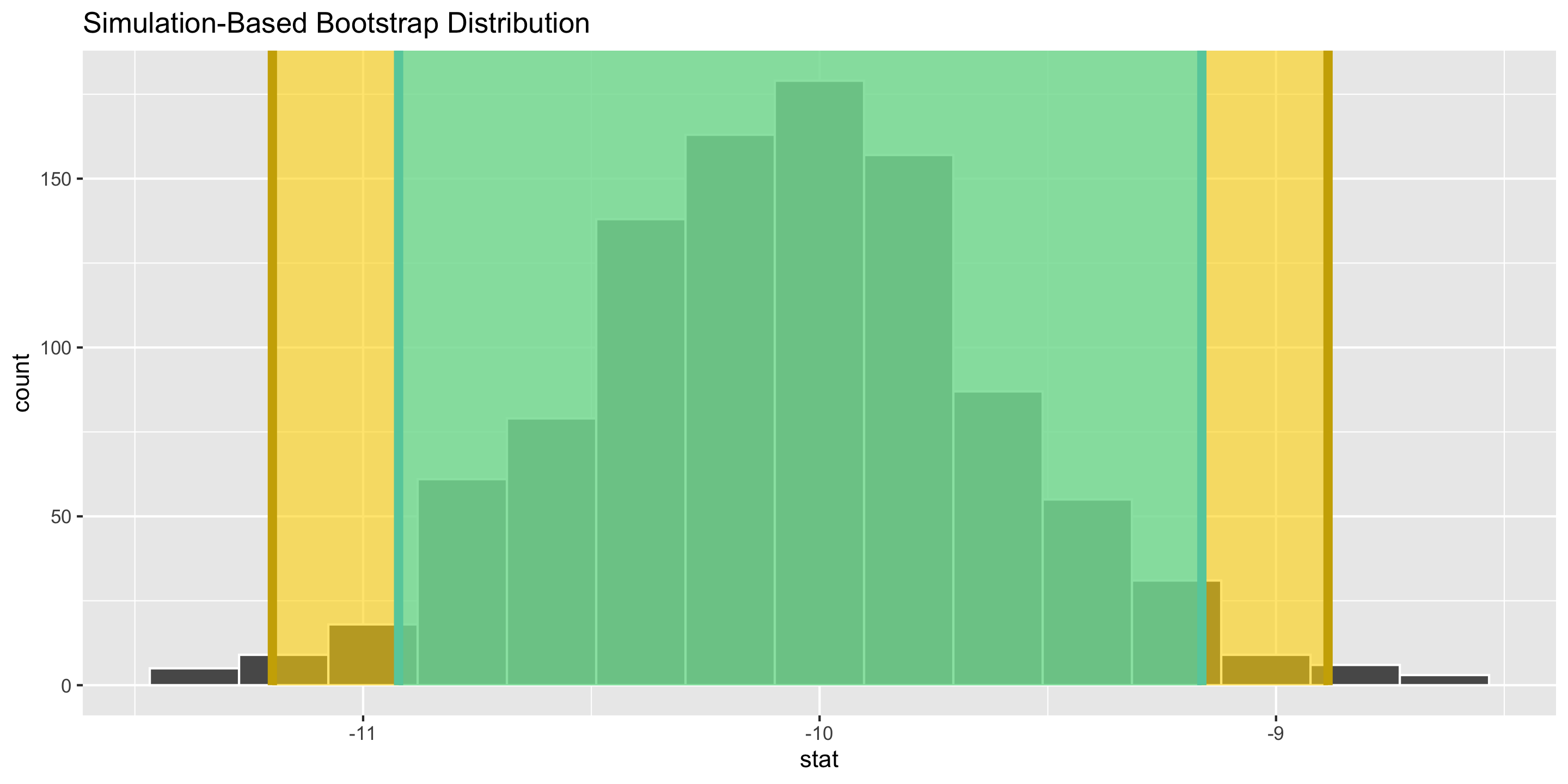
Bootstrapped Confidence Intervals
Two Methods
Assuming random sample and roughly bell-shaped and symmetric bootstrap distribution for both methods.
Interpretation: The point estimate is -10.04mm. I am 95% confidence that the difference in bill length between Adelie and Chinstrap penguins is, on average, between -10.92mm and -9.16mm.