\(H_o: \beta_j = 0\), \(H_A: \beta_j \neq 0\). For \(j > 0\), we are testing if there is a difference from the baseline group. For \(j = 0\) we are testing if the baseline group is different than 0.
What sort of test might we want to carry out more often?
Inference for Many Means
Inference for Many Means
Consider the situation where:
Response variable: quantitative
Explanatory variable: categorical
Parameter of interest: \(\mu_1 - \mu_2\)
This parameter of interest only makes sense if the explanatory variable is restricted to two categories.
Can use linear regression but in the special case of categorical explanatory variables, we have another option.
It is time to learn how to conduct inference for more than two means.
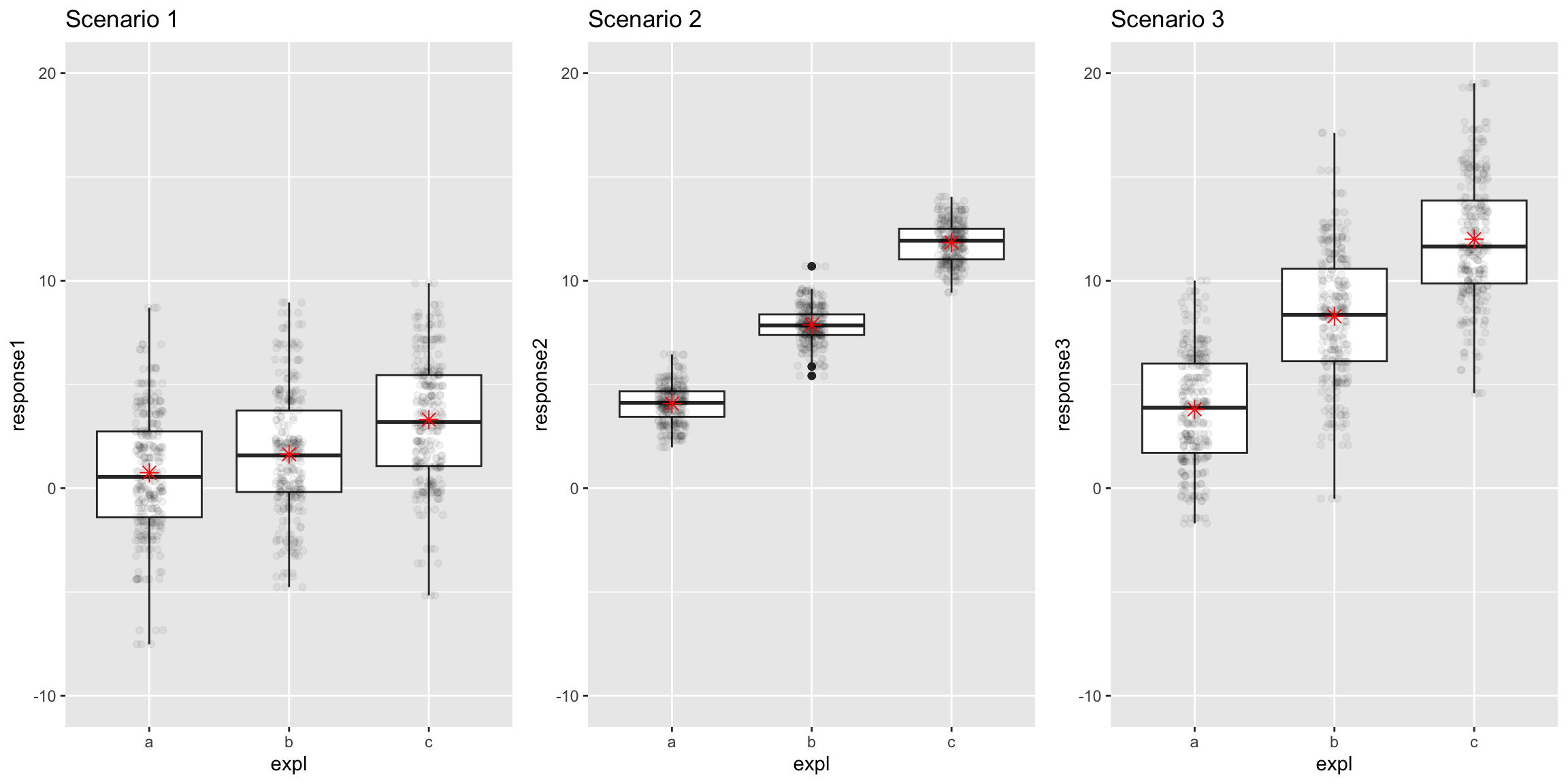
Now we can create a test statistic that compares these two measures of variability.
Test Statistic
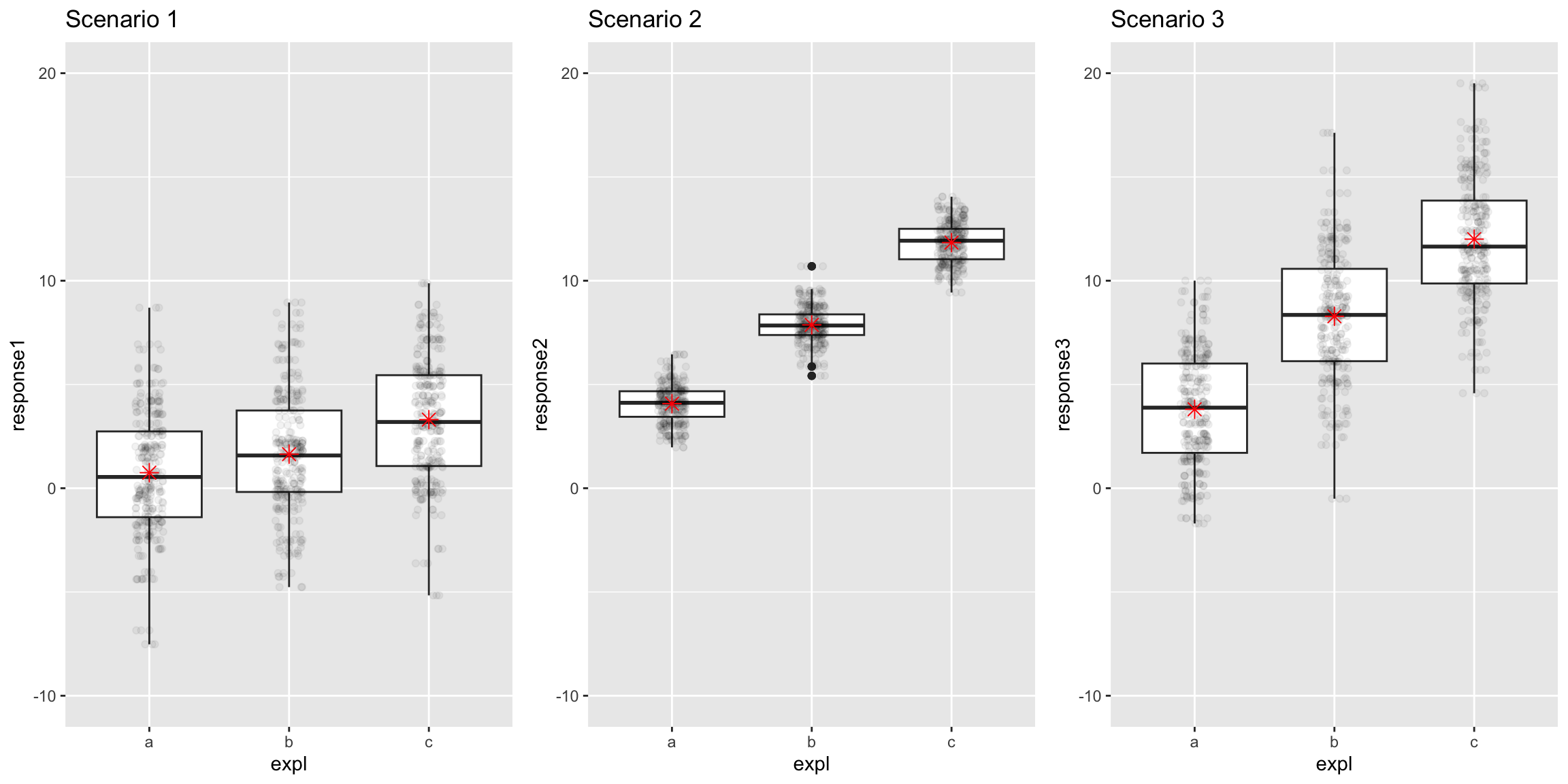
In some ways, MSG is the natural test statistic but as we saw for this example, MSG alone isn’t enough.
Scenarios 2 and 3 have roughly the same MSG but we are much more convinced that the means are different for 2 than 3.
That is where MSE comes in!
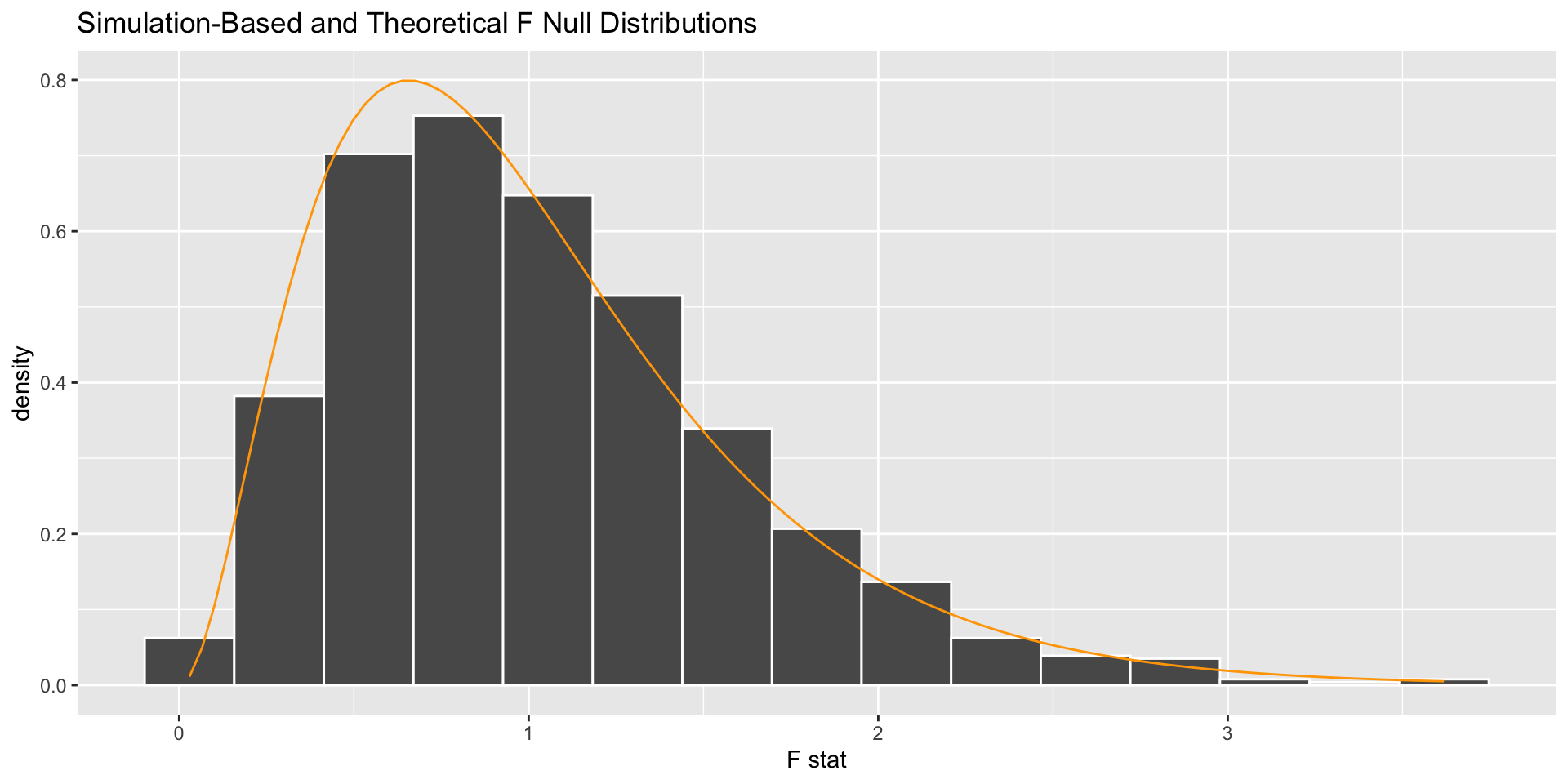
Test Statistic
\[
F = \frac{\mbox{MSG}}{\mbox{MSE}} = \frac{\mbox{variance between groups}}{\mbox{variance within groups}}
\]
If \(H_o\) is true, then \(F\) should be roughly equal to what?
If \(H_a\) is true, then \(F\) should be greater than 1 because there is more variation in the group means than we’d expect if the population means are all equal.
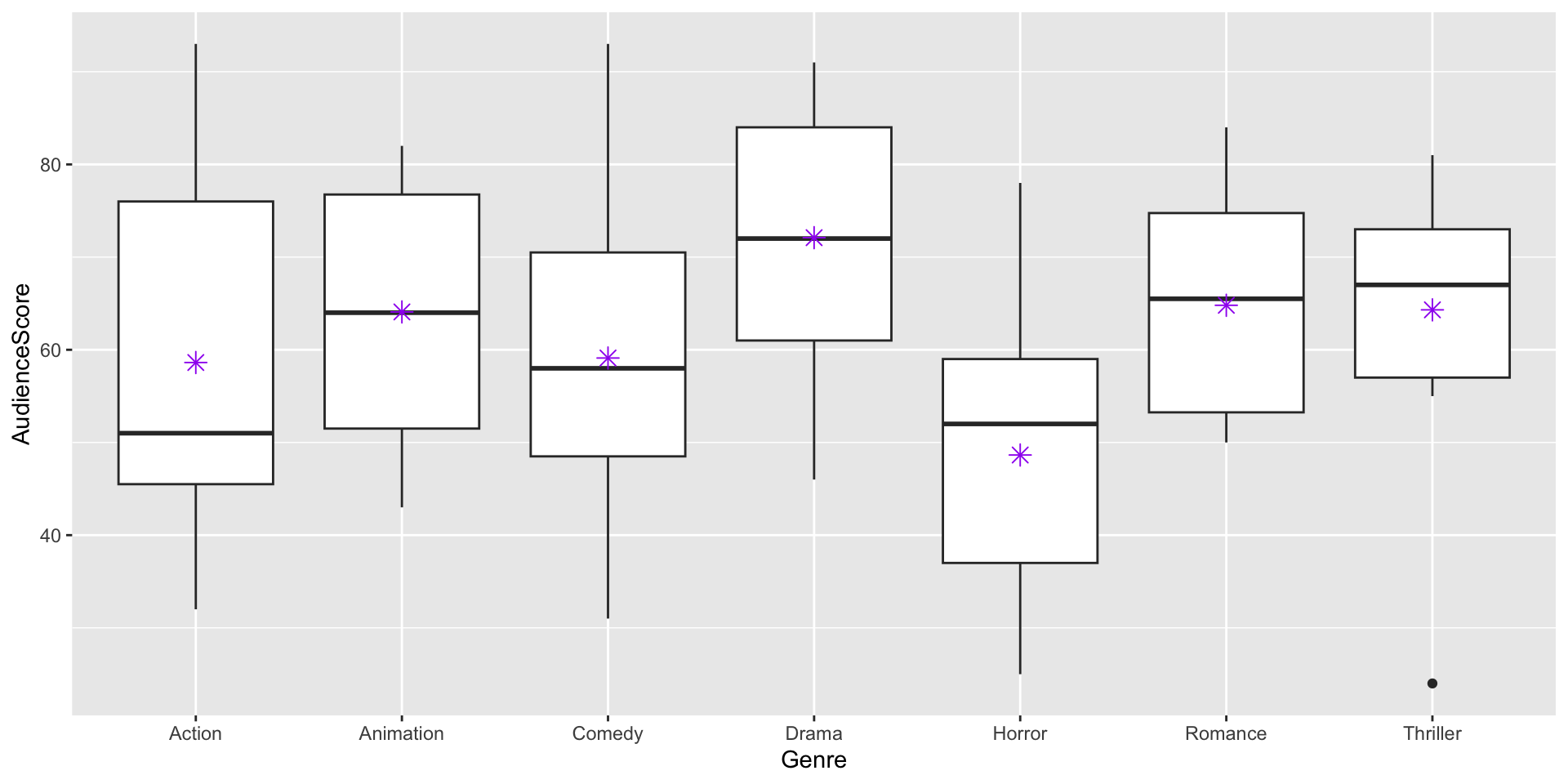
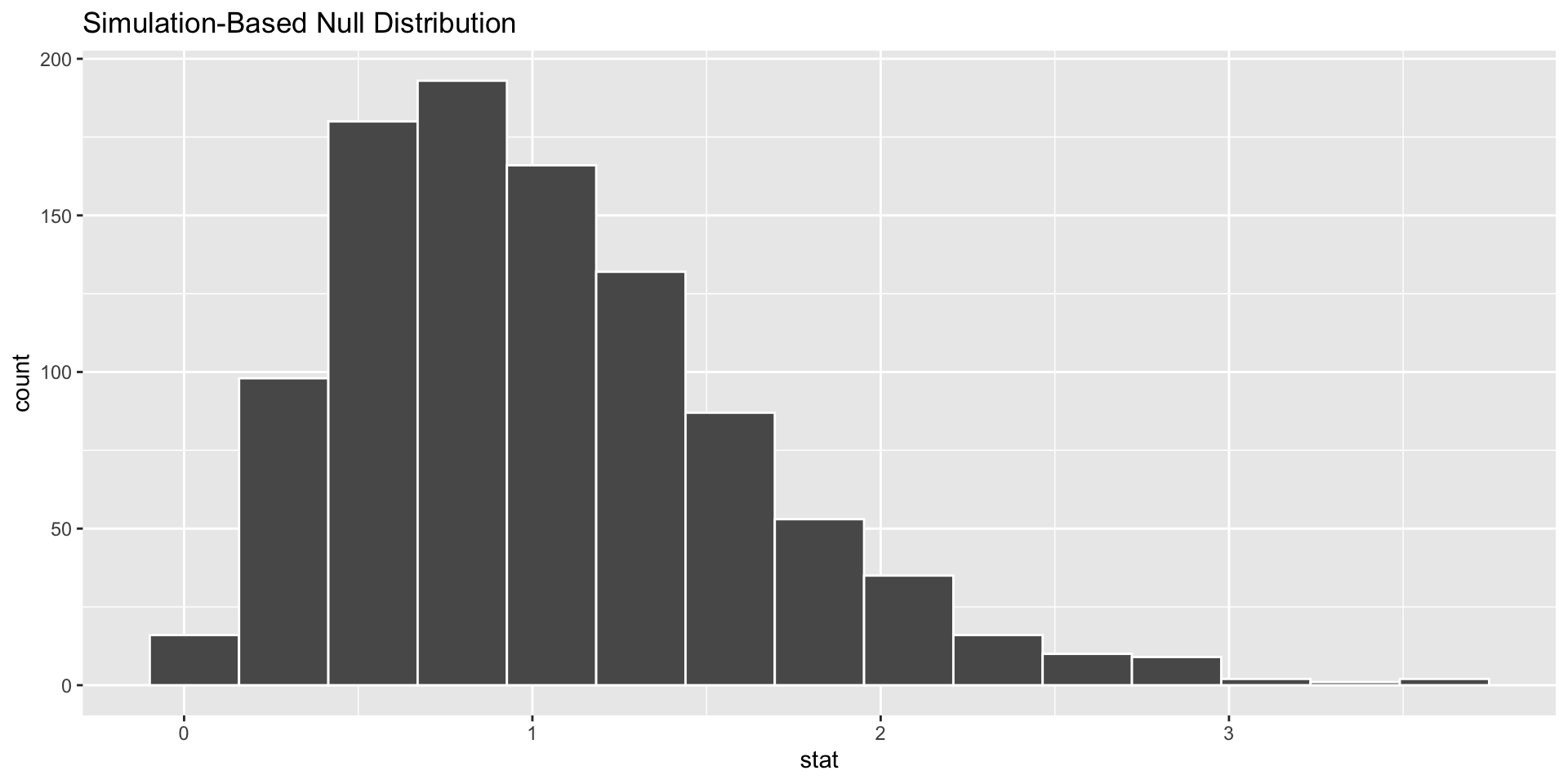
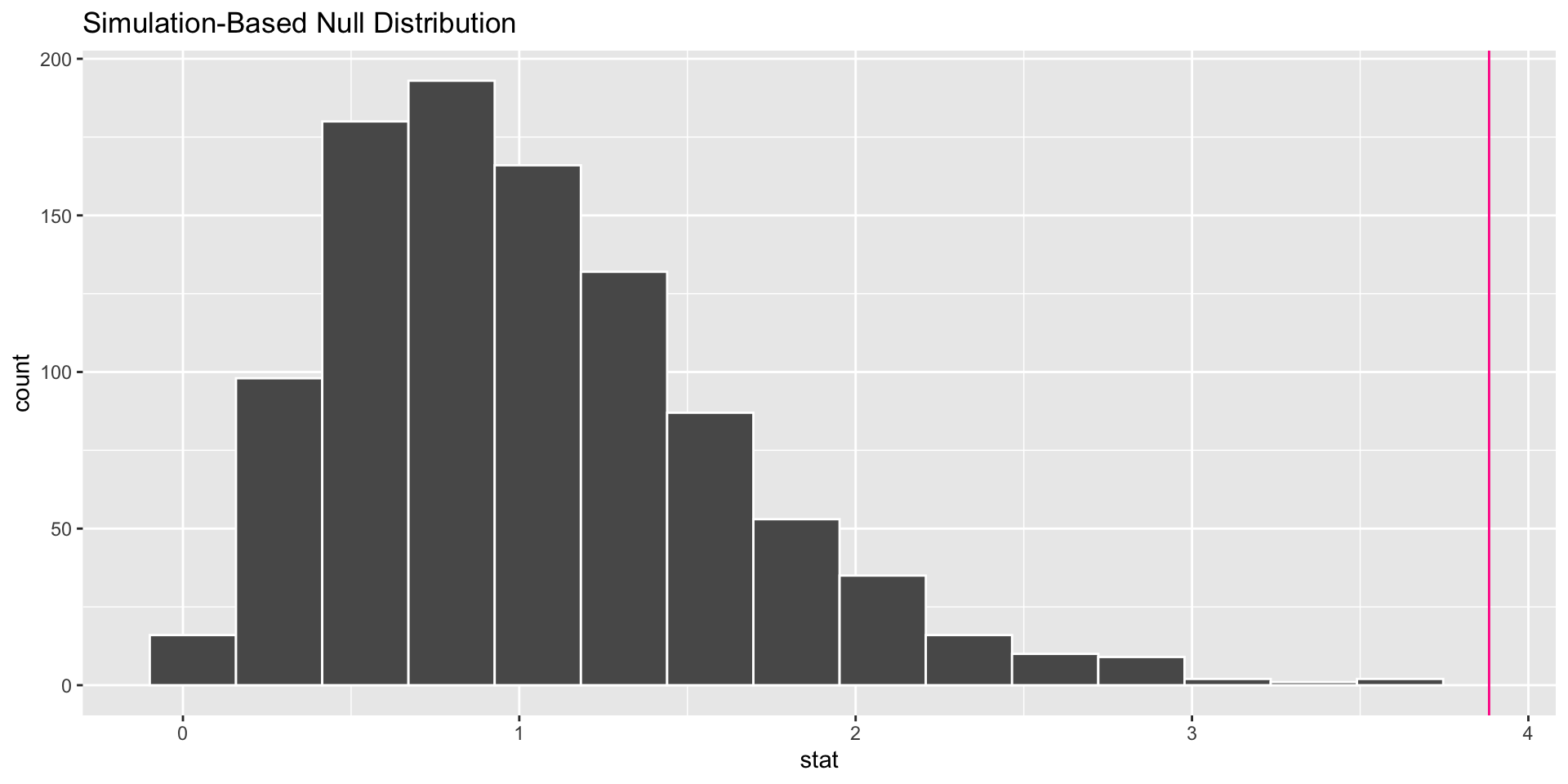
Returning to the Movies Example
library(infer)#Compute F test stattest_stat <- movies %>%specify(AudienceScore ~ Genre) %>%calculate(stat ="F") test_stat
Response: AudienceScore (numeric)
Explanatory: Genre (factor)
# A tibble: 1 × 1
stat
<dbl>
1 3.88
Is 3.88 a large test statistic? Is a test statistic of 3.88 unusual under \(H_o\)?