Continuing our Discussion of Moving Beyond BINARY Categorical Variables
Inference for Categorical Variables
Consider the situation where:
Response variable: categorical
Explanatory variable: categorical
Parameter of interest: \(p_1 - p_2\)
This parameter of interest only makes sense if both variables only have two categories.
It is time to learn how to study the relationship between two categorical variables when at least one has more than two categories.
Hypotheses
\(H_o\): The two variables are independent.
\(H_a\): The two variables are dependent.
Example
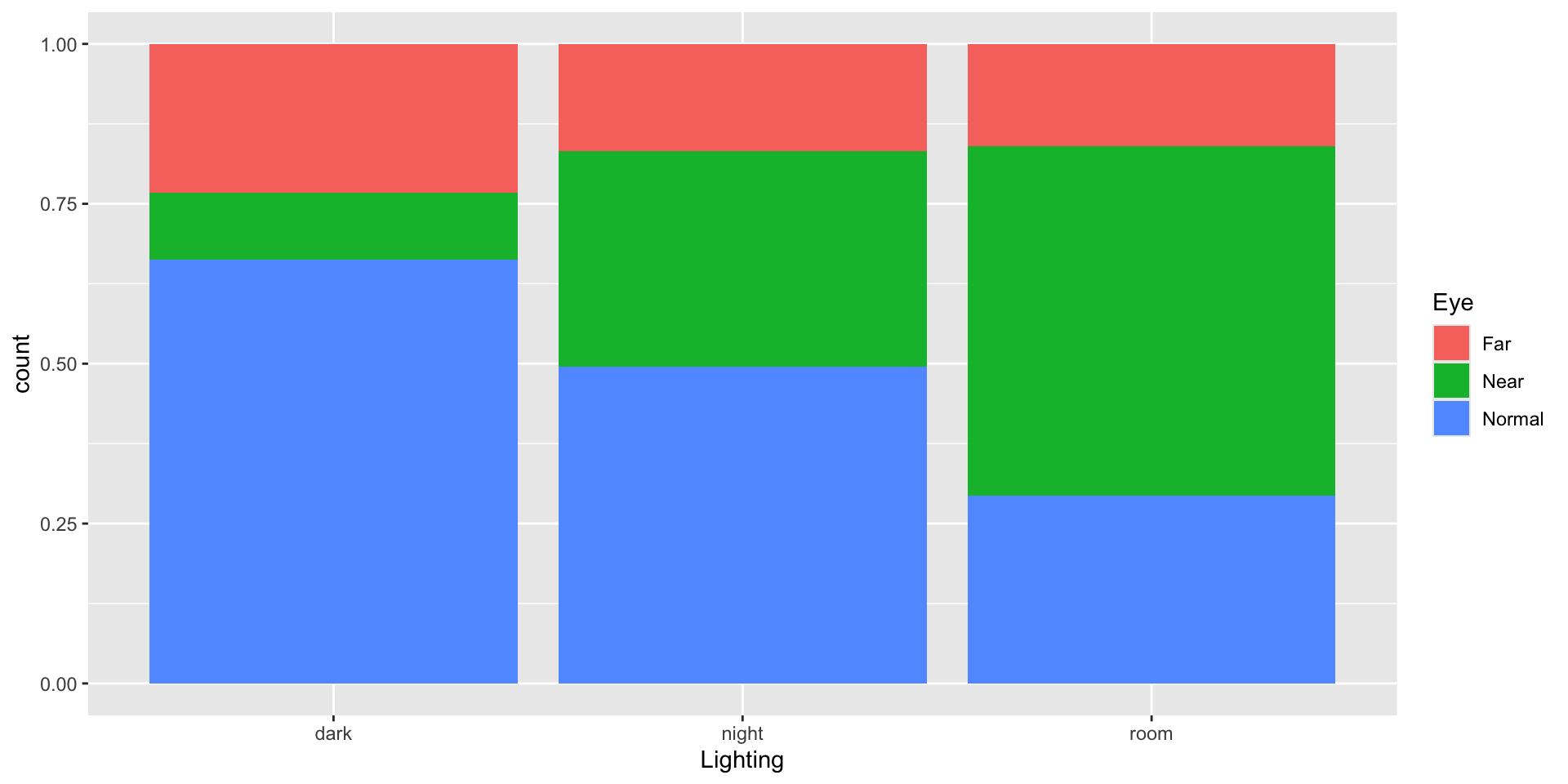
Near-sightedness typically develops during the childhood years. Quinn, Shin, Maguire, and Stone (1999) explored whether there is a relationship between the type of light children were exposed to and their eye health based on questionnaires filled out by the children’s parents at a university pediatric ophthalmology clinic.
# A tibble: 9 × 3
Lighting Eye n
<chr> <chr> <int>
1 dark Far 40
2 dark Near 18
3 dark Normal 114
4 night Far 39
5 night Near 78
6 night Normal 115
7 room Far 12
8 room Near 41
9 room Normal 22
Eyesight Example
Does there appear to be a relationship/dependence?
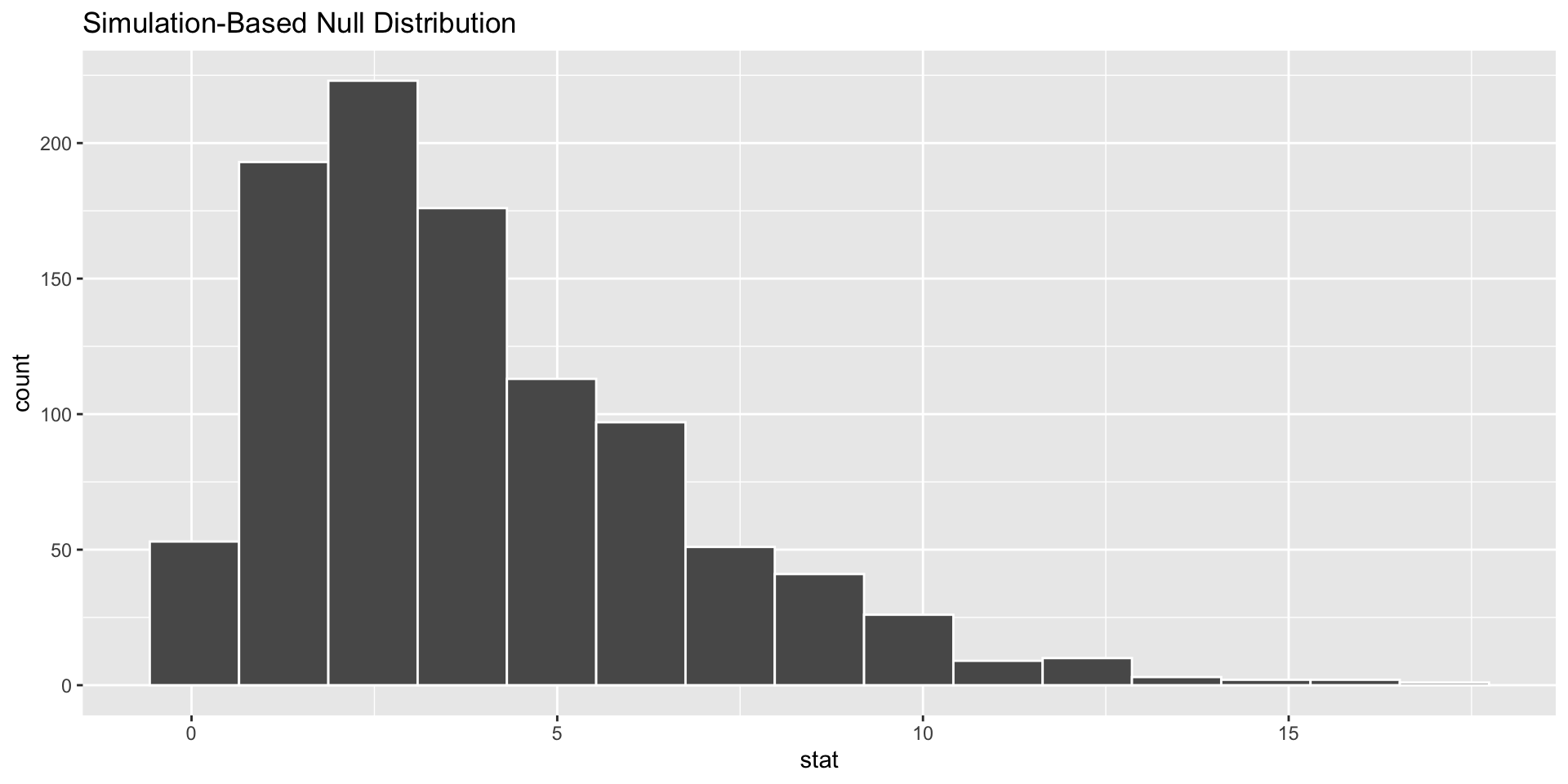
# Compute p-valuenull_dist %>%get_pvalue(obs_stat = test_stat, direction ="greater")
# A tibble: 1 × 1
p_value
<dbl>
1 0
Approximating the Null Distribution
If there are at least 5 observations in each cell, then
\[
\mbox{test statistic} \sim \chi^2(df = (k - 1)(j - 1))
\] where \(k\) is the number of categories in the response variable and \(j\) is the number of categories in the explanatory variable.
The \(df\) controls the center and spread of the distribution.