
Logistic Regression
Grayson White
Math 141
Week 14 | Fall 2025
Undergraduate Forestry Data Science Summer Research
This summer, I’ll be hiring Reed students in my undergraduate forestry data science (UFDS) program!
UFDS is a long-running collaboration with the US Forest Service where we answer statistical and data science research questions for the US Forest Service.
Students will work on problems generated by the Forest Service and will collaborate directly with Research Statisticians and Foresters at the Forest Service.
Co-directed by myself and Kelly McConville (Bucknell University), this summer’s research will occur on Reed’s campus and will include students from both colleges!

Undergraduate Forestry Data Science Summer Research
This summer, I’ll be hiring Reed students in my undergraduate forestry data science (UFDS) program!
Students will work in small groups on multiple projects throughout the summer. Some tentative projects for this summer:
- In recent years, FIA has experienced greater need for estimates of forest parameters over smaller geographic regions. For example, the Forest Service manages wild fires and tries to estimate the impact of these fires on important forest attributes. This area of research is called small area estimation. This project will explore the utility of several different estimators for estimating forest attributes over small areas.
.png)
Undergraduate Forestry Data Science Summer Research
This summer, I’ll be hiring Reed students in my undergraduate forestry data science (UFDS) program!
Students will work in small groups on multiple projects throughout the summer. Some tentative projects for this summer:
- Bayesian statistics is a field of statistics we have discussed but not engaged in this semester. The Forest Service is interested in using Bayesian statistics and models to operationalize small area estimation, but they need guidance on the mechanics of fitting these models. This project will first learn about, and then write a tutorial on, operationalizing Bayesian small area estimation for the forest service and in forest inventory settings more generally.
Undergraduate Forestry Data Science Summer Research
This summer, I’ll be hiring Reed students in my undergraduate forestry data science (UFDS) program!
Students will work in small groups on multiple projects throughout the summer. Some tentative projects for this summer:
- Simulation studies are crucial for understanding the properties of model-based estimators. And recently, the Forest Service has been interested in assessing estimators that account for change in the forest (from, e.g., a forest fire or clearcut). In this project, students will adapt the KBAABB methodology to help assess estimators that estimate change.

Undergraduate Forestry Data Science Summer Research
This summer, I’ll be hiring Reed students in my undergraduate forestry data science (UFDS) program!
Some tentative details (subject to change):
10 week program, starting June 1, 2026.
Stipend included (approx: $6000)! (Actual amount and housing details TBD)
Ice cream excursions and lots of fresh fruit included!
We are planning to open applications over the break or in the first week of Spring semester. So be on the lookout! (I will send an email to you all)
What should I expect from a day of research?
- The work will be highly collaborative. Most days we will have a team meeting in the morning where everyone presents their progress, discusses issues, and talks through their next steps. For the rest of the day, your time will likely be split between your projects and will be a mix of coding, writing, problem-solving, and dealing with merge conflicts in GitHub.
How do I apply?
Wait for the Summer 2026 application to be posted this winter break (or in the first week of Spring semester). I’ll email you all once I have posted it!

Example
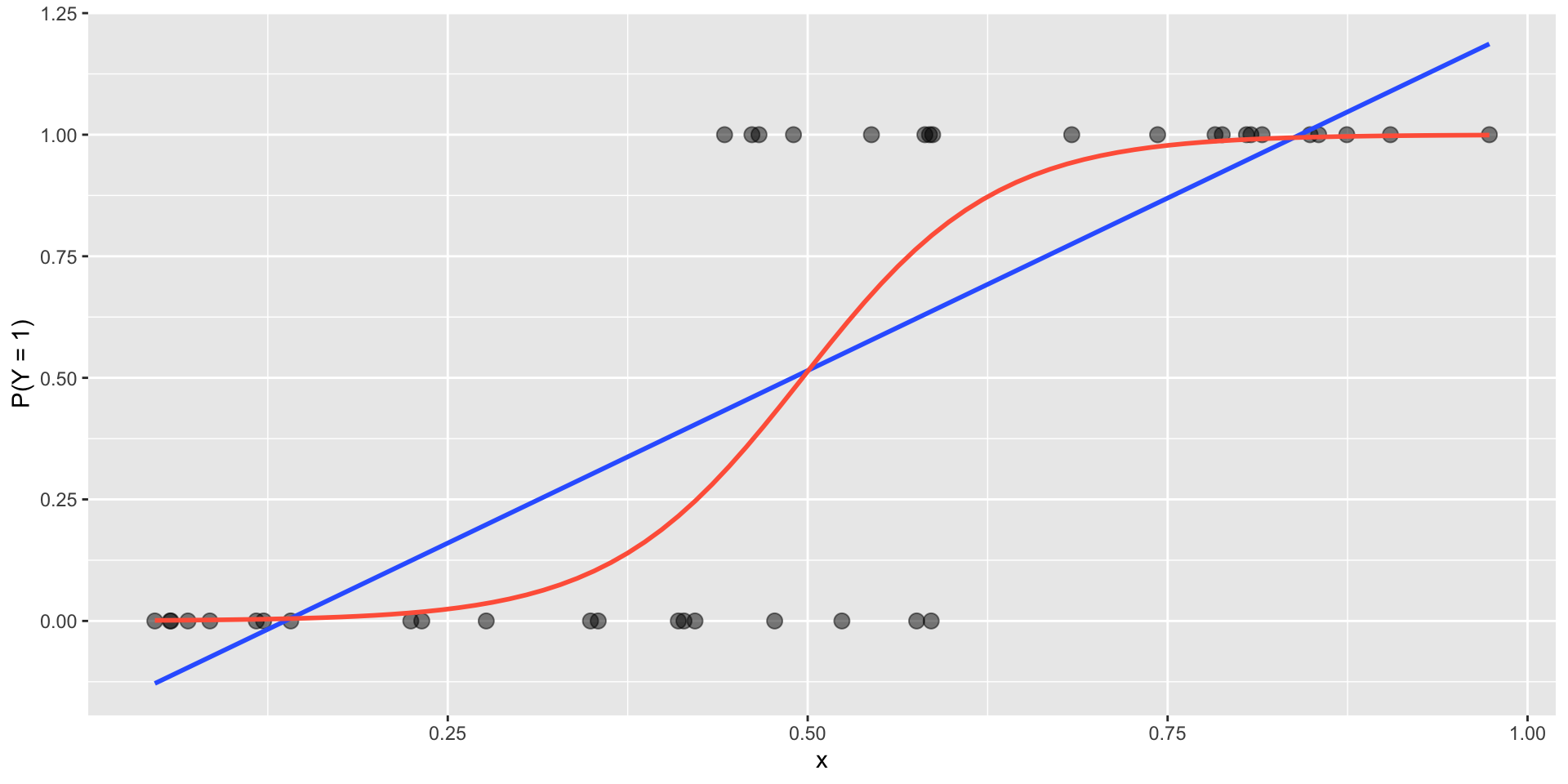
Let’s look at the forested R package that contains a dataset on whether a given location in Washington state is considered to be “forested” or not (by the US Forest Service’s definition of “forested”). We’ll ask the question: Can we build a model to predict whether or not a location is forested given some useful predictors derived from satellite imagery and other remote sensing products?

Example
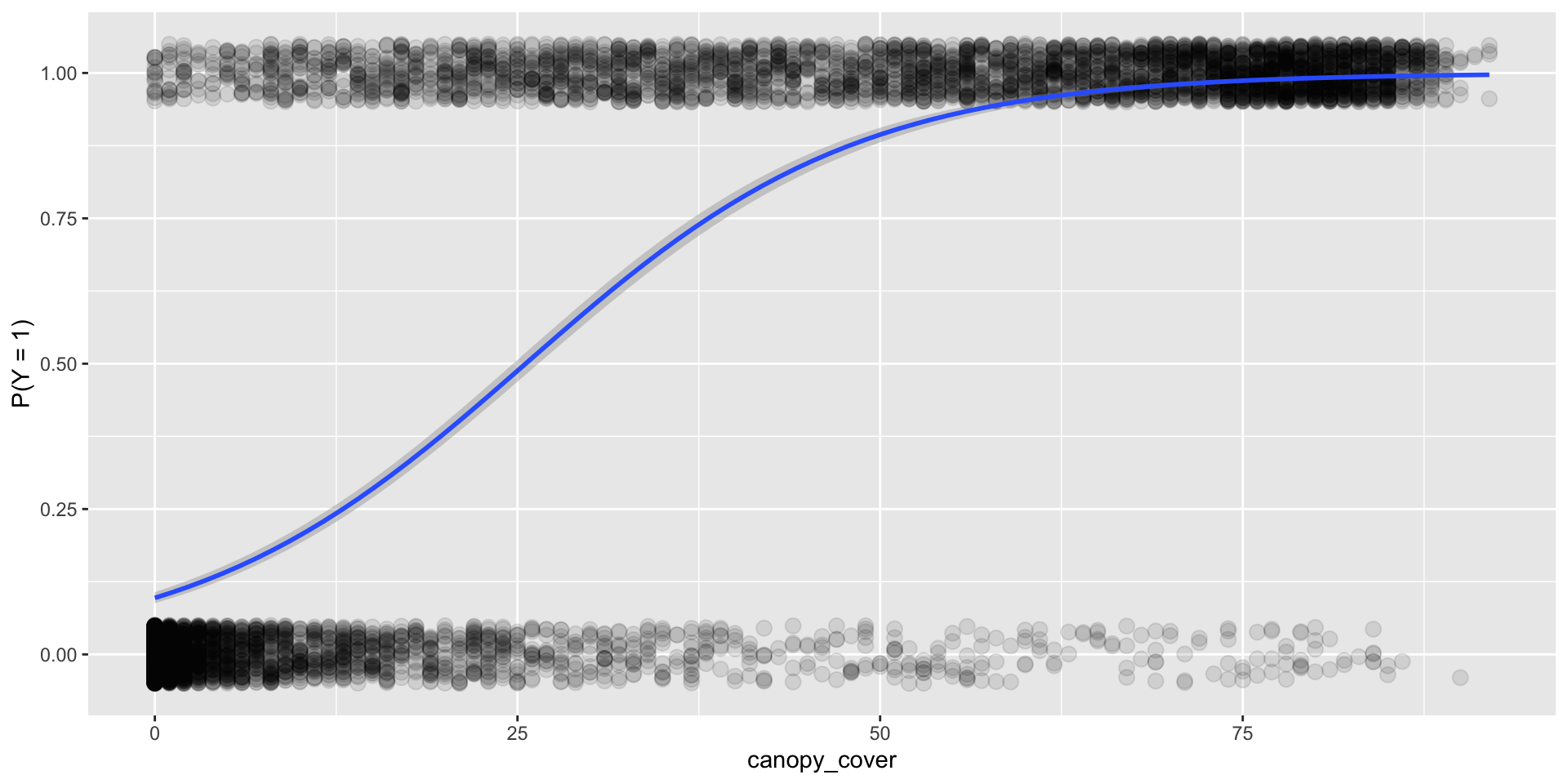
Example
This is what an helpful explanatory variable looks like!
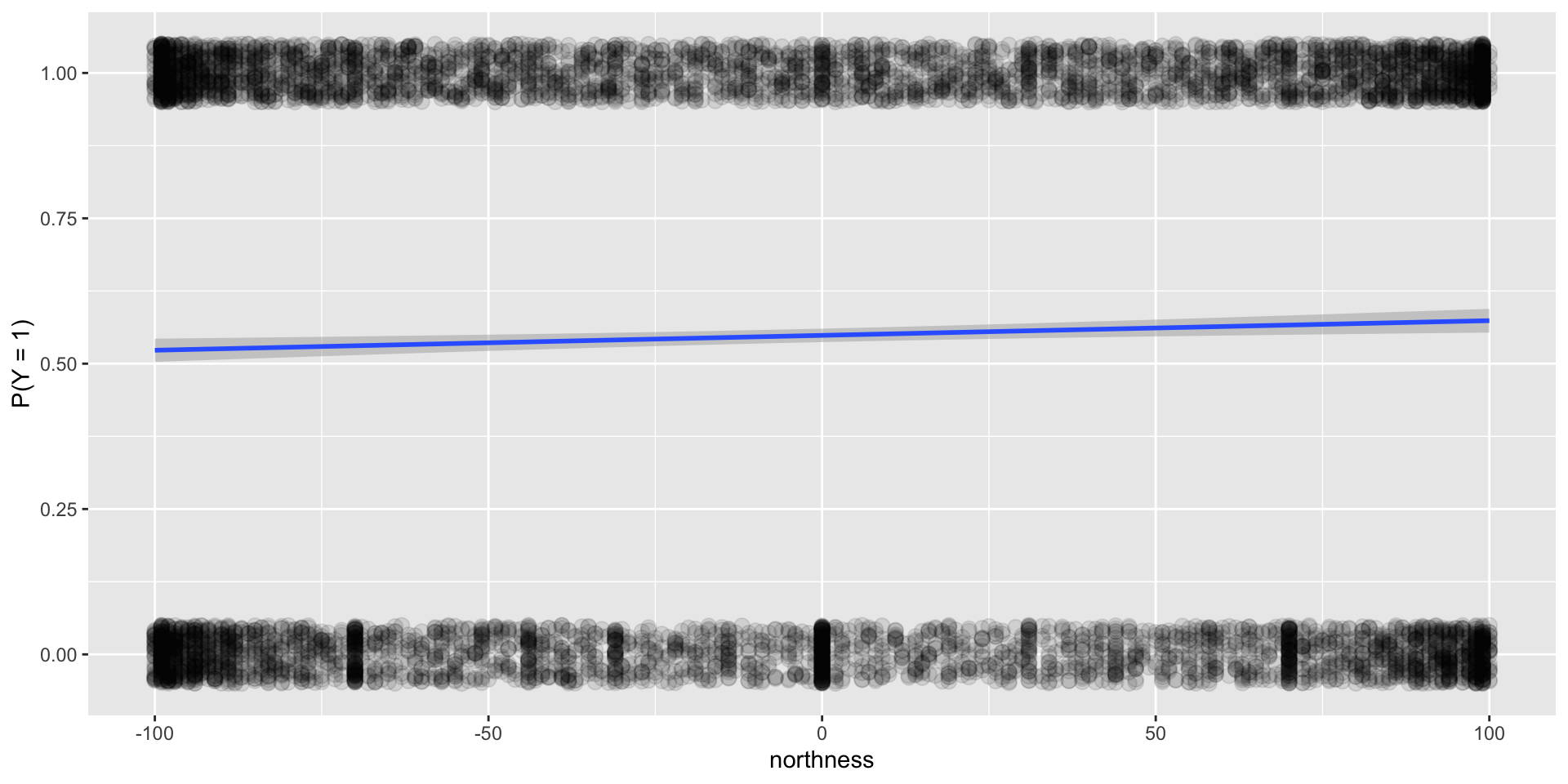
This is what an unhelpful explanatory variable looks like!